HZERO PaaS平台组装笔记(十一)AI平台安装
本文是H-ZERO 安装部署笔记,出于学习研究目的,刚开始按照开放平台->社区与合作伙伴->文档中心- 《HZERO 轻量版》技术文档进行部署实践,选择快速开始->微服务版进行安装; 但作为初学者, 水平太低, 由于轻量版合并了多个微服务,要改各种配置,过程中遇到多个困难,没有搞定🙂, 后来按照 开放平台->社区与合作伙伴->文档中心- 《HZERO汉得企业级PaaS平台》 技术文档进行 标准版(没有合并微服务的版本) 安装部署实践 ,安装部署成功了。本系列文章记录了这个过程。
需要说明的是,如果不是出于学习研究目的,是不需要这么麻烦的,技术中心有发发行版,可以一键安装,一小时不到可以全部安装完成。
本文是出于学习研究目的,按照技术文档从制品库里面拿各种零件进行组装,所以过程会比较繁琐,供学习研究参考。
实践系统环境:windows自带的Linux虚拟机 WSL ,linux版本在微软应用商店选择 Ubuntu22.04
十一、AI平台安装
参考开放平台/AI平台的安装部署文档:
一、中间件安装
AI平台新增使用多个中间件,milvus(向量库)、neo4j(图数据库)、elasticsearch(全文检索)、hkms(指示检索和切片)、hpye(python沙箱)
开放平台提供了Docker 的部署方式,依赖的中间件软件提供了默认的 docker-compose 部署方式(要求Docker/Docker CE >= 19.x)
请先下载下面提供的安装介质,并解压到安装环境。
hzero-aigc-docker-compose-1.6.0-ALPHA.zip
配置调整之后,只需要依次进入每个目录,运行 docker-compose up -d 命令启动组件即可。
启动完成后通过 docker ps -a 命令查看容器状态。
要使用Docker, 我们windows系统已经安装了docker desktop , 带的docker引擎是v28.04的,完全满足要求; 只需要在设置中跟我们hzero虚拟机做个整合,我们的虚拟机就能用docker了,所有的WSL虚拟机可以共享windows主机的docker, 不用重复安装;
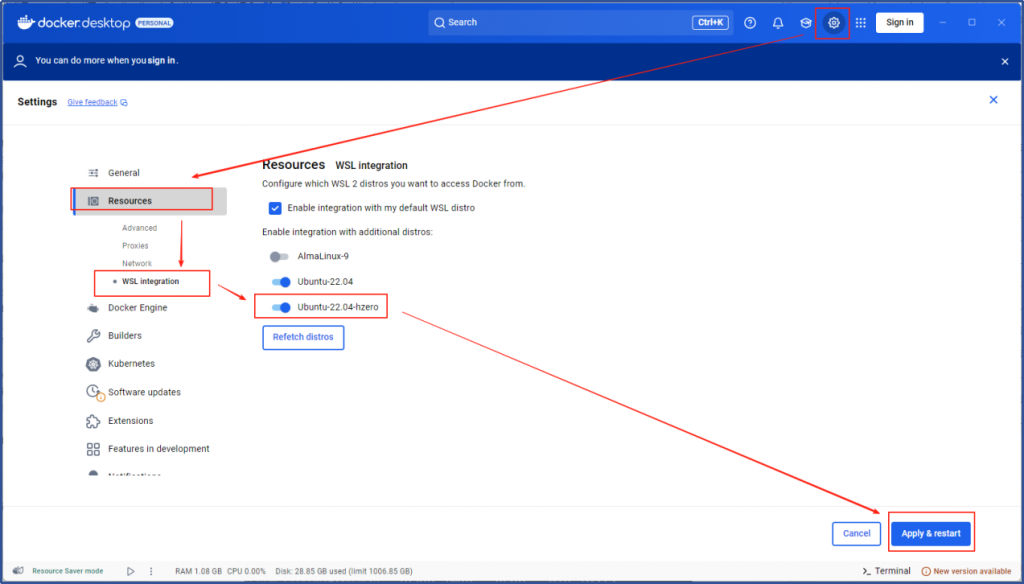
开放平台提供的docker镜像中除了新增的中间件,还包括了已经安装的mysql,Redis,MongoDB ,这些因为我们之前在本机已经安装了,就不需要用docker另外再启服务了。 之前我们没有安装的中间件就用开放平台提供的镜像把它启起来。
二、中间件配置和启动
在HKMS的服务配置中,对于MongoDB 的要求是得有个hgpt数据库;
# MongoDB地址
MONGO_CONN: mongodb://<username>:<password>@127.0.0.1:27017/hgpt?authSource=admin&authMechanism=SCRAM-SHA-1
admin> db.grantRolesToUser(“hzero”, [
… { role: “readWrite”, db: “hgpt” },
… { role: “dbAdmin”, db: “hgpt” }
… ])
{ ok: 1 }
创建完成后可以验证下:
mongosh “mongodb://hzero:hzero@localhost:27017/hgpt?authSource=
admin&authMechanism=SCRAM-SHA-1″
Es服务
Docker 服务 Es配置,按照开放平台文档启动ES的docker服务时,拉elasticsearch 镜像报错。问了姜州,他说他可以拉,那文档没错,怀疑是主机代理问题,把主机代理clash关闭后就可以正常拉了。
在 目录下运行 docker-compose up -d, 下拉镜像并启动服务
root@desktop-jacksen:/d02/hzero-aipaas/hzero-aigc-docker-compose/elastic# docker-compose up -d
WARN[0000] /d02/hzero-aipaas/hzero-aigc-docker-compose/elastic/docker-compose.yml: the attribute `version` is obsolete, it will be ignored, please remove it to avoid potential confusion
[+] Running 11/11
✔ elasticsearch Pulled 58.7s
✔ 0c64192e9533 Pull complete 0.1s
✔ 70c9415a17bd Pull complete 0.1s
✔ 4f4fb700ef54 Pull complete 0.0s
[+] Running 2/2
✔ Network aigc Created 0.1s
✔ Container elasticsearch Started
ElasticSearch 容器启动完成之后,需先将插件拷贝到容器内部:
docker cp analysis-icu-8.12.2.zip elasticsearch:/usr/share/elasticsearch
docker cp analysis-ik-8.12.2.zip elasticsearch:/usr/share/elasticsearch
拷贝没成功;
在执行 安装ES插件的时候报错,说容器没启动,但尝试去启动容器后几秒钟,容器就自动down了,把日志给元宝分析,元宝说是内存配置问题,默认会使用宿主机内存的一半,我们linux虚拟机分配了25G内存,它用一半就是12.5G,日志中显示用了12.5G,元宝说大概率会导致OOM,但我去syslog中没查到oom错误。 元宝说原来的ES 的docker的内存配置有问题:
environment:
– ELASTIC_PASSWORD=elastic
– discovery.type=single-node
– xpack.security.enrollment.enabled=true
– xpack.security.enabled=true
– m=1GB
这里 – m=1GB ,这种配置,现在docker不认,要改成:
– ES_JAVA_OPTS=-Xms500m -Xmx500m # ✅ 设置 JVM 堆内存为 500MB
改了之后重启,依然几秒后就down了,不过这次错误原因说是 获得文件锁失败,元宝说是权限问题,我是用共享的windows主机上的docker desktop,他使用的系统用户是Windows的用户a, 这个用户在linux中创建的/d02/hzero-aipaas/hzero-aigc-docker-compose/elastic/volumes 目录上没有权限,但这个在配置文件中被配置成被docker容器使用,所以就出问题了,解决方案是改变权限:
chown -R 1000:1000 /d02/hzero-aipaas/hzero-aigc-docker-compose/elastic/volumes/elastic
或者:
chmod 777 -R /d02/hzero-aipaas/hzero-aigc-docker-compose/elastic/volumes(个人机用推荐)
检查并停止冲突进程
docker ps -a | grep elasticsearch
docker stop 83c184ba23c4 && docker rm 83c184ba23c4
再启动:
docker start elasticsearch
这次成功了;
先将插件拷贝到容器内部:
docker cp analysis-icu-8.12.2.zip elasticsearch:/usr/share/elasticsearch
docker cp analysis-ik-8.12.2.zip elasticsearch:/usr/share/elasticsearch
然后进入ES容器内:
docker exec -ti elasticsearch /bin/bash
安装ES插件:
bin/elasticsearch-plugin install file:/usr/share/elasticsearch/analysis-icu-8.12.2.zip
bin/elasticsearch-plugin install -b file:/usr/share/elasticsearch/analysis-ik-8.12.2.zip
退出ES容器
Ctrl+P+Q
重启ES:
docker restart elasticsearch
ES链接的密码在yml文件中可以查到: ELASTIC_PASSWORD=elastic
Mivilus服务
Miviuls 容器启动脚本中添加内存限制:
sudo docker run -d \
–memory=”600m” \
–memory-swap=”600m” \
否则会使用很大内存,导致内存不够用,但内存放到600m,实际使用向量是仅用于个人学习,测试,不能超过5万条向量,超过内存不够用,需要扩内存,重启。
启动mivilus服务 可以正常启动:
HKMS服务
这是一个python服务, 经测试内存在2G都会出现OOM,我把内存上限放到了3g, 没有再出现oom错误
Neo4j
在yml中配置,设置内存500M,上限1G;
– ES_JAVA_OPTS=-Xms500m -Xmx500m # 设置 JVM 堆内存为 500M
deploy: # 限制容器总内存(Docker Compose v2.3+)
resources:
limits:
memory: 1g # 容器最大内存(建议为 JVM 内存的 1.5~2 倍)
验证可用性:

密码在配置文件中可以查到:- NEO4J_AUTH=neo4j/password
HKMS
HKMS的内存要设置到3G,否则会报OOM启动不了;这个比较吃内存
HPYE
HPYE的内存可设置到500M
注意这是python应用,不能用xms 和xmx 设置内存,只能用:
deploy: # 限制容器总内存(Docker Compose v2.3+)
resources:
limits:
memory: 500m # 容器最大内存(python应用直接限制内存大小)
这些容器启动后的内存消耗情况:
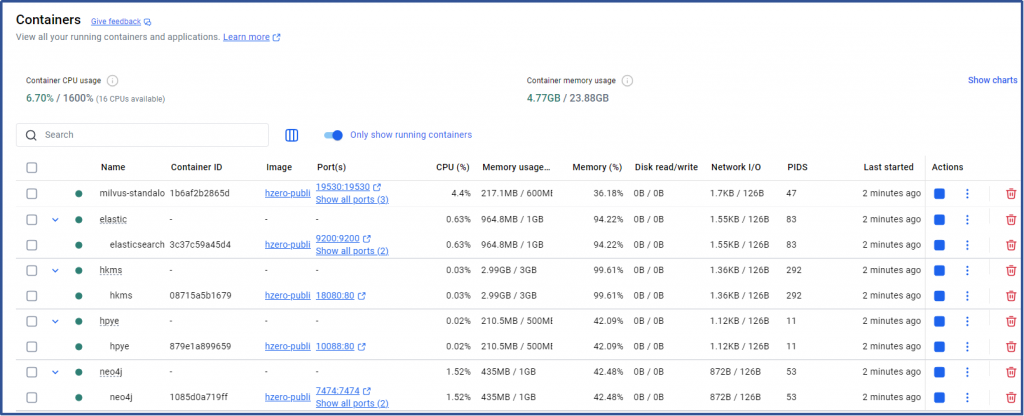
三、微服务安装
到选配平台,参考部署文档,以hzero 1.12.1 父组件开始,把hzero-aip-server和hzero-aip-app选配下来:
1、种子数据安装:
2、启动 aip-server 服务
1.1 编辑服务的application.yml文件在数据库链接rul中添加:allowPublicKeyRetrieval=true
server-uri改一下
1.2因为yml配置文件中要用到MongoDB , 且要求的URI配置是: uri: ${SPRING_DATA_MONGODB_URI:mongodb://hzero:hzero@mongo.hzero.com.cn:27017/haip?authSource=admin}
所以需要创建hzero用户 和 db “haip”
root@desktop-jacksen:/d02/hzero-aipaas/resource-package# mongosh
test> use admin
switched to db admin
admin> db.createUser({
… user: “hzero”,
… pwd: “hzero”,
… roles: [
… { role: “readWrite”, db: “haip” }, // 允许读写haip数据库
… { role: “dbAdmin”, db: “haip” } // 允许管理haip数据库(如创建索引)
… ]
… })
{ ok: 1 }
admin>
完成后可用命令验证下: mongosh “mongodb://hzero:hzero@localhost:27017/haip?authSource=
admin”
1.3 编辑 服务的bootstrap.yml 文件,在 spring.cloud层级下添加网卡选择:
inetutils:
# 设置首选网卡,对于本机有多块网卡的情况,可以设置首选网卡来注册
# 指定忽略的网卡
ignored-interfaces[0]: lo
# 选择注册的网段
preferred-networks[0]: 172.18.14.48
文档和选配平台的版本是1.6.0.ALPHA,实际制品库中没有,要改成1.6.0.ALPHA.1.15
1.4 把原来服务模块下的run.sh 和stop.sh都拷贝过来;
编辑run.sh ,把端口号改成跟服务的 bootstrap.yml文件中定义的端口号一致,把 AGENT 变量改成
-javaagent:/d02/hzero/project/ps-license/licenseAgent/license-agent111.jar
构建成功,但启动失败,看日志是 java.io.FileNotFoundException有点像Licens 服务的Agent版本问题, mvn dependency:tree 命令看license 版本是1.1.2 版本的,按理说用license-agent111.jar是对的。
跟姜州沟通,他先让我在POM中,在dependencies前面加这个试试:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty-bom</artifactId>
<version>4.1.116.Final</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
试了一下,发现错误依旧,然后又让我把选配出来的POM中的这一段删除掉,说这段版本不对,要去掉。
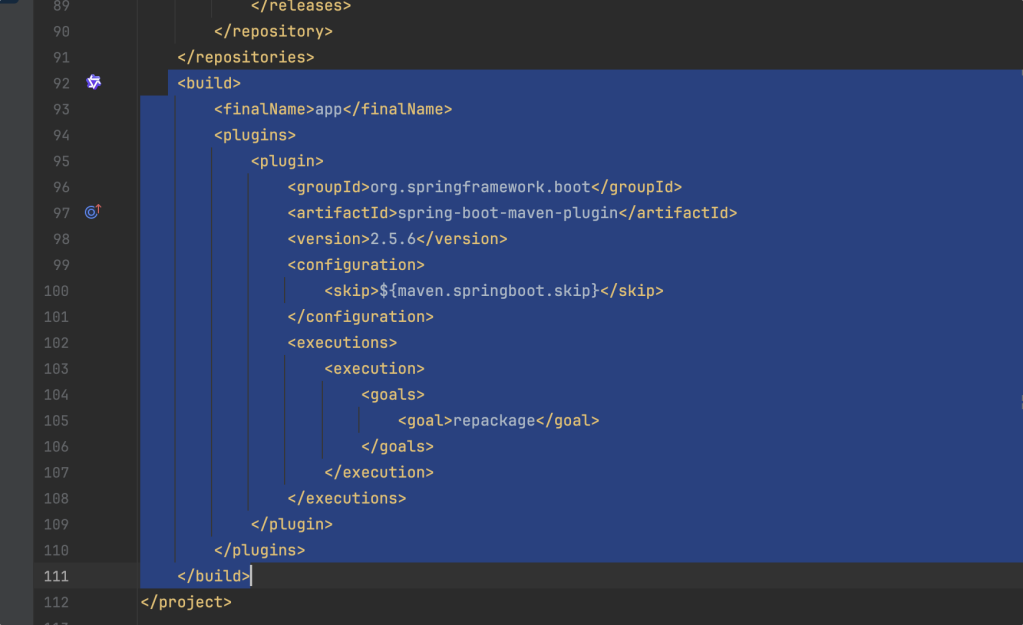
再次尝试,发现就OK了
但这个服务似乎特别吃资源:长期耗掉2G的内存资源(只给它分配了1G)
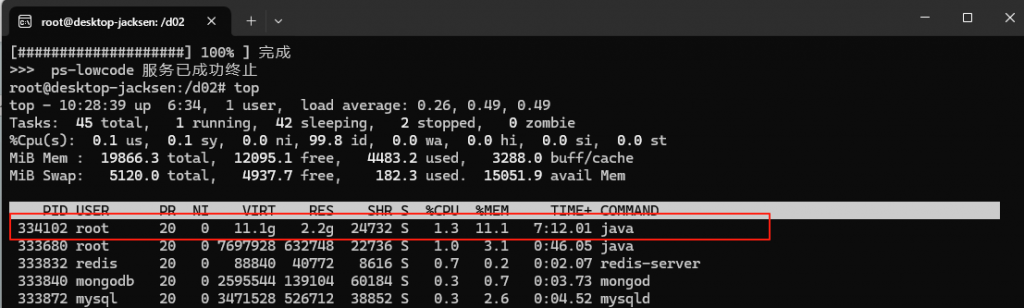
看日志是调用Schedule服务没成功(没启这个服务),另外就是一直显示线程池的信息;
2025-07-18T10:32:50.093+08:00 INFO 334102 — [hzero-aip] [pool-3-thread-3] org.hzero.core.util.CommonExecutor : [>>ExecutorStatus<<] ThreadPool Name: [monitor], Pool Status: [shutdown=false, Terminated=false], Pool Thread Size: 0, Largest Pool Size: 0, Active Thread Count: 0, Task Count: 0, Tasks Completed: 0, Tasks in Queue: 0
把启动内存调整到2G再试,用jhsdb jmap –heap –pid 335142看内存长期要消耗1.6G
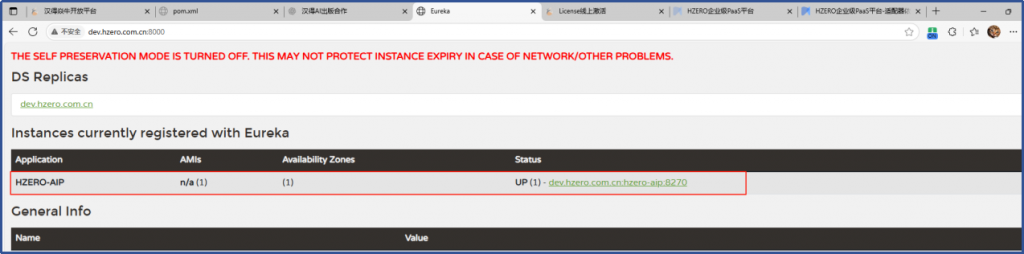
注册中心已经可以看到了:
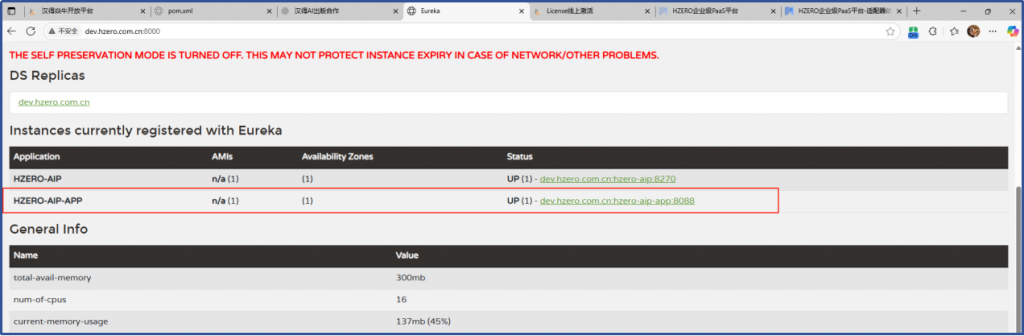
1、启动 aip-app 服务
所需配置更改鱼aip-Server 类似,服务启动后注册中心可见
jhsdb jmap –heap –pid 336108
Heap Usage:
G1 Heap:
regions = 2048
capacity = 2147483648 (2048.0MB)
used = 1799735976 (1716.3619766235352MB)
free = 347747672 (331.63802337646484MB)
83.80673713982105% used
jhsdb jmap –heap –pid 335142
Heap Usage:
G1 Heap:
regions = 2048
capacity = 2147483648 (2048.0MB)
used = 1730237952 (1650.08349609375MB)
free = 417245696 (397.91650390625MB)
80.57048320770264% used
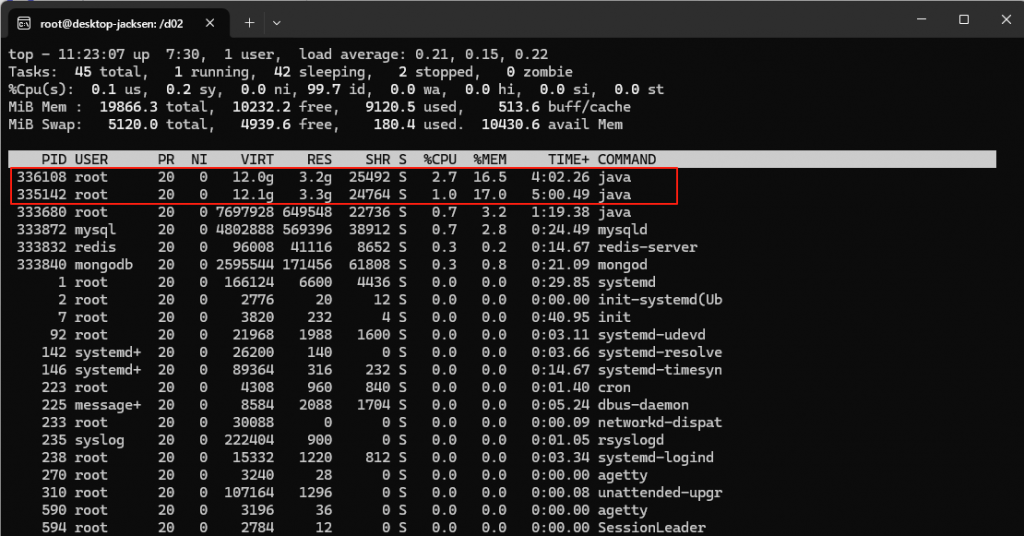
AI平台的这两个java服务 (进程ID分别为336108和335142 ) 耗内存比较大,若以jmap 看,内存消耗1.6+1.7 =3.3G,但在linux操作系统层面却消耗了20G*(16.5%+17%)=6.7G,这是为什么呢?
元宝分析给了差异本质:操作系统统计的RES包含JVM堆内存+堆外内存+共享库,而jmap仅显示堆内存
从wsl的Linux的top命令看,3个Java服务长期占了7.2G内存:但是WSL windows的资源管理器看整个WSL虚拟机只占了3.3G。假设我在一套真正的Linux服务上运行微服务,内存需求我应该参考哪个呢?
元宝回答:
原因解释:为什么Windows显示更少?
- WSL2的动态内存回收:WSL2使用的VM会主动将Linux子系统中的空闲内存返还给Windows主机。
- 内存压缩技术:WSL2使用内存压缩减少实际物理内存占用。
- 缓存统计口径:Linux将磁盘缓存(buff/cache)计入”used”,而Windows不计入VmmemWSL的内存占用。
真正的Linux推荐内存配置公式
服务总内存=(所有进程RES总和)×1.2+系统预留
四、AI平台功能验证
1、点击 企业应用库/个人问答时错误
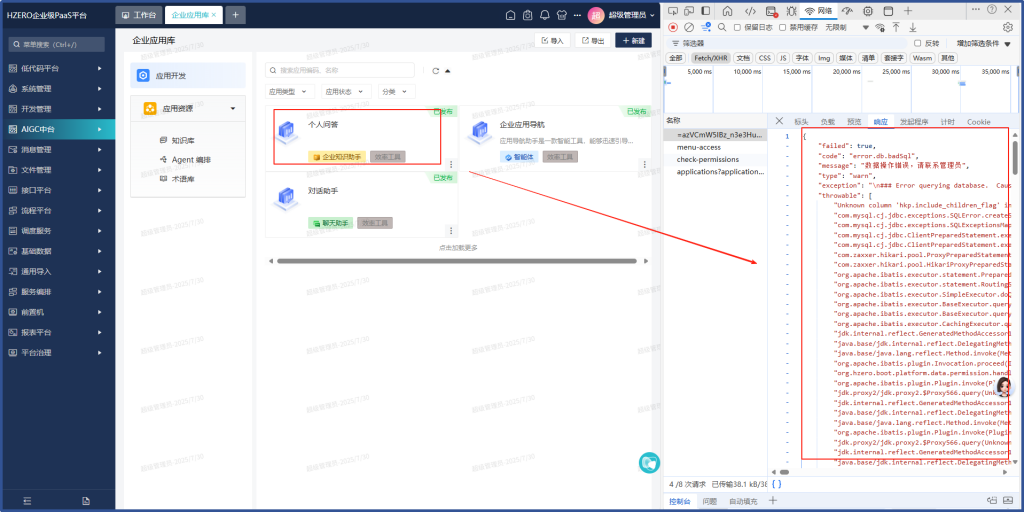
点击 企业应用库/个人问答 时出现错误;元宝分析日志后指出的问题是:
错误原因分析:未知字段引用
- 错误信息:Unknown column ‘hkp.include_children_flag’ in ‘IN/ALL/ANY subquery’
- 直接原因:SQL语句中引用了表别名 hkp(对应表 haip_knowledge_permission)的字段 include_children_flag,但该字段在数据库表中实际不存在。
- 具体位置:错误发生在权限控制的子查询中(涉及组织架构和职位的权限校验逻辑)
解决方案:添加缺失字段
ALTER TABLE haip_knowledge_permission
ADD include_children_flag TINYINT(1) DEFAULT 0 COMMENT ‘是否包含子节点:0否,1是’;
跟姜州沟通了下,他说选配平台的种子数据可能有问题,要用他发的种子数据,我把版本号报给他,他发了一个新版的1.6 alpha版种子数据给我;
停AI服务,升级数据库种子数据;
升级种子数据第2步和第3步会报错,
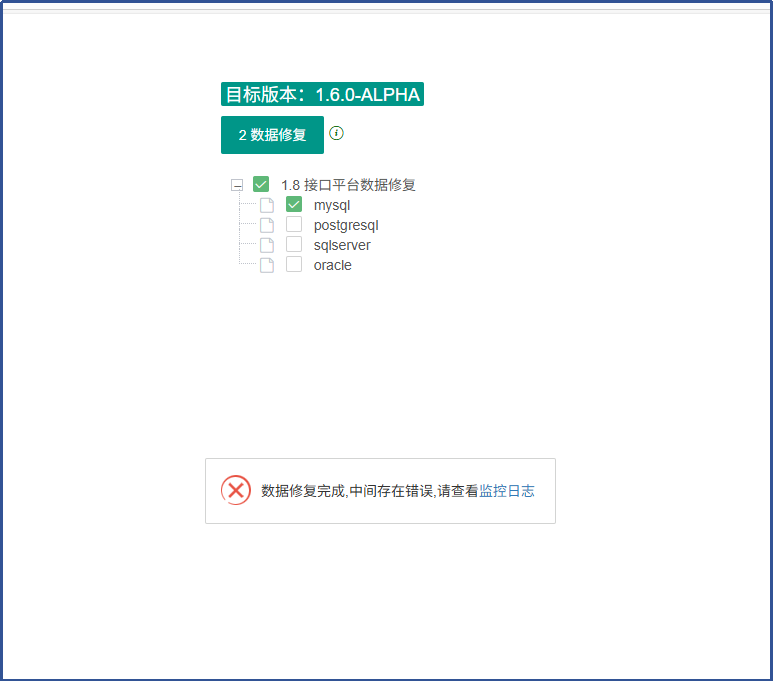
其中第2步报错信息:
日志如下:
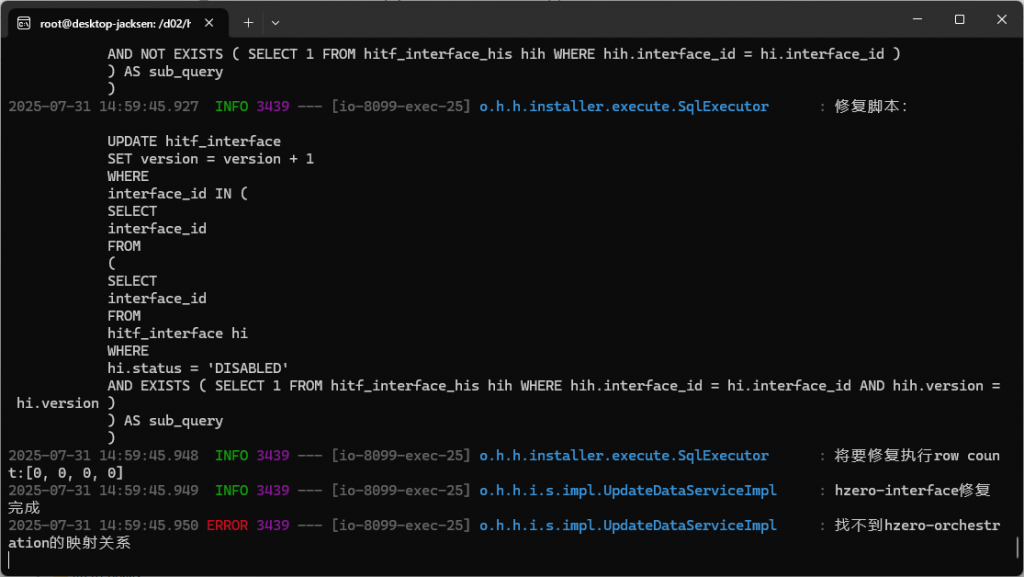
解决方案:
在service-mapping.xml里面加了一条
<service name=”hzero-orchestration” filename=”hzero_orchestration” schema=”hzero_orchestration” description=”集成平台-服务编排”/>

其中第3步,按照姜州提示,hzero_workflow和hzero_alert不要勾选,再次运行第3步,这次把这两个勾选去掉,就可以了(备注种子数据脚本是可以重复执行的,他的执行逻辑是略过已有数据,是增量更新,对于少数系统数据会执行覆盖更新,对于最终客户经常可能修改的数据不会覆盖)
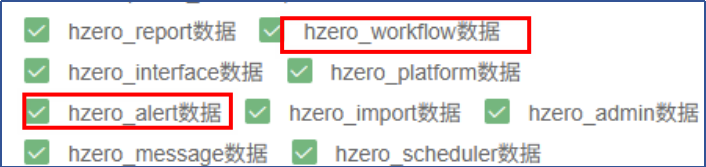
升级好种子数据之后,这个问题就解决了。
问题解决。
2、MCP插件中心报页面不存在
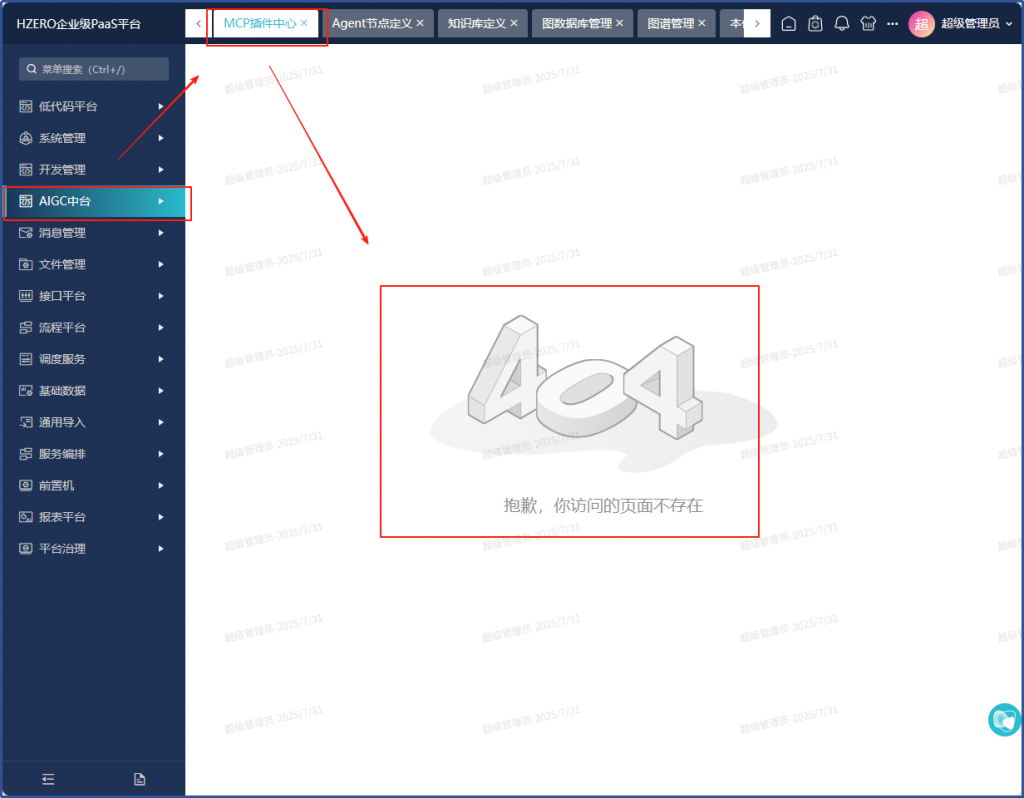
查看原来的hzero_front_aip的前端版本是7月19日构建的1.2.0-alpha.2版本
我们曾经单独构建过工作流的前端,也因为集成平台的问题更新过另外两个微服务的前端,我们先去看看最新的AI前端的版本是多少?
我们到 /d02/hzero/front/front目录下
现在 package.json文件中加一个前端模块:
“hzero-front-haip” : “~1.2.0-alpha.2”,
在当前当前选配工程的front目录下执行yarn(这一步是把最新的版本拉到node_moudules目录下):
之后运行npx umi hzero-info 查看当前yarn拉下来的新的模块版本:
hzero-front-haip version : 1.2.0-hzerocli.0
把package.json中的hzero-front-haip版本设置成新的1.2.0-hzerocli.0
然后单独构建 hzero-front-haip
yarn run build:ms hzero-front-haip
Done in 204.82s.
root@desktop-jacksen:/d02/hzero/front/front#
4、再把新的dist目录拷贝到原来位置,更改目录权限,再执行run-front.sh 替换字符串
cp -rf /d02/hzero/front/front/dist /d02/hzero/front/
sudo chown -R www-data:www-data /d02/hzero/front/dist
sudo chmod -R 755 /d02/hzero/front/dist
cd /d02/hzero/front/
./run-front.sh
重启服务后,经测试,发现问题依旧。
姜州说前端版本太低了,他给的AI平台的前后端版本是:
hzero-aip-server 1.6.0.ALPHA.2
hzero-aip-app 1.6.0.ALPHA.2
hzero-front-haip 1.6.0-alpha.2
hkms 1.6.0
在package.jason中把前端版本设置到1.6.0-alpha.2,然后yarn, 再npx umi hzero-info
hzero-front-haip version : 1.6.0-alpha.0-ys-9
重新构建。出现错误,看起来是hzero-front库里面的文件;应该需要更新hzero-front
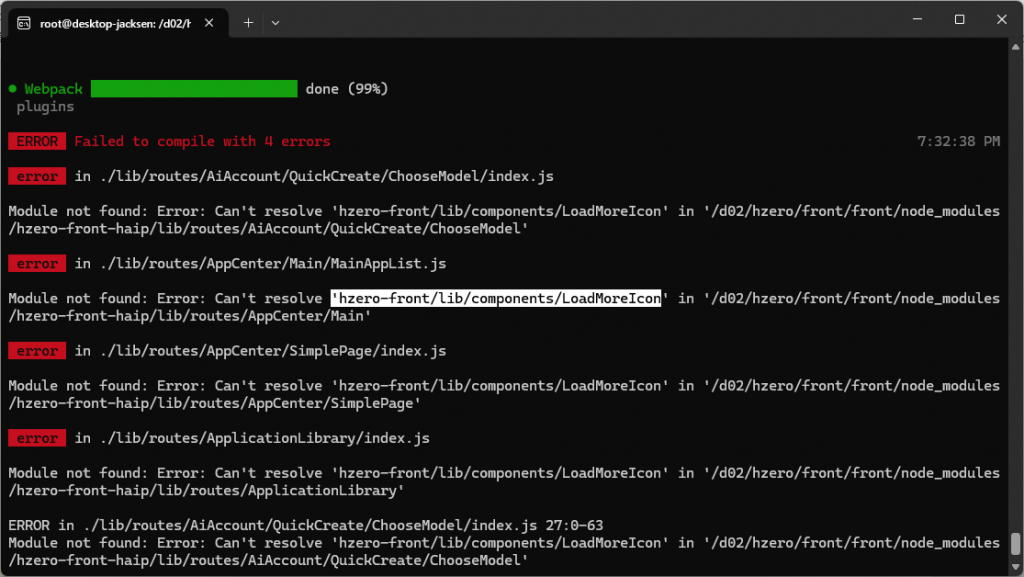
问了前端架构组,需要把hzero-front 升级到1.12.4-alpha.11才有这个文件;
Package.json中把hzero-front设置成1.12.4-alpha.11,然后yarn 获得库依赖文件 , 然后重新build,
yarn run build:ms hzero-front-haip
Done in 305.25s.
root@desktop-jacksen:/d02/hzero/front/front#
这次成功了,再次启动服务测试:发现出了其他问题:
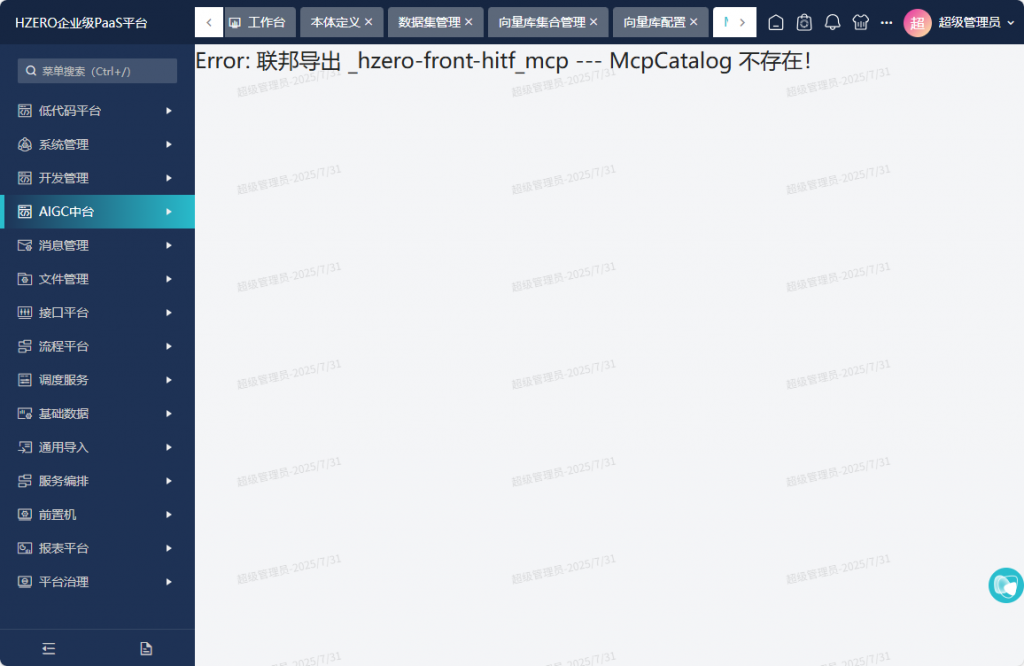
而且其他好多界面也不正常,还不如原来那个版本;
跟姜州沟通了下,说1.6.0-alpha.0-ys-9这个版本不对,姜州问了前端,前端说1.6.0-alpha.2这个版本早就推到制品库了(最新的都2.1了)
问豆包,说是版本的模糊匹配导致的,解决方案是在package.json中把版本好前面的~去掉,强制精确匹配。
再次yarn , 然后在yarn.lock中搜索hzero-front-haip ,可以看到要求的版本和实际匹配的版本是一致了。
hzero-front-haip@1.6.0-alpha.2:
version “1.6.0-alpha.2”
重新build:
yarn run build:ms hzero-front-haip
再把新的dist目录拷贝到原来位置,更改目录权限,再执行run-front.sh 替换字符串
cp -rf /d02/hzero/front/front/dist /d02/hzero/front/
sudo chown -R www-data:www-data /d02/hzero/front/dist
sudo chmod -R 755 /d02/hzero/front/dist
cd /d02/hzero/front/
./run-front.sh
经测试,这个问题依然存在, 姜州说要把接口平台和集成平台的前置机两个模块的前端也更新到新的版本:
“hzero-front-hitf”: “1.12.1-beta.1”,
“jipaas-front-jitf”: “1.8.0-alpha.1”,
我先看下我现在的版本:
我目前的hzero-front-hitf 是1.12.1-beta.4 版本的,满足要求,jipaas-front-jitf 不存在
加到package.json中去单独build jipaas-front-jitf ,yarn后build
yarn run build:ms jipaas-front-jitf
经测试,依然有问题:
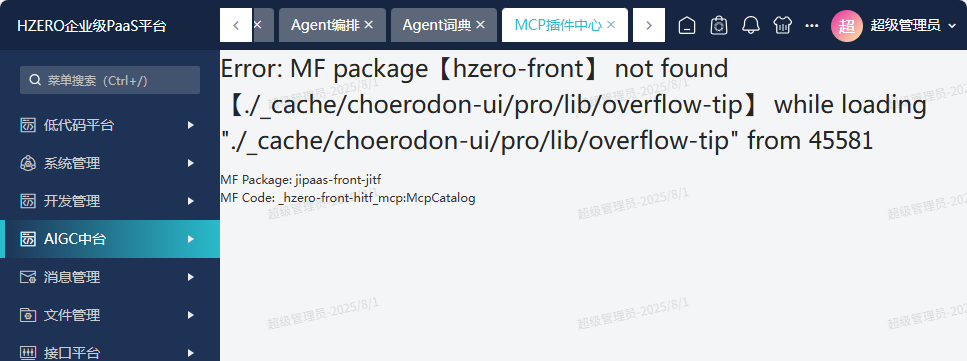
看起来是hzero-front缺东西,考虑上次按照前端架构组建议把hzero-front版本在 package.json中改成1.12.4-alpha.11 版本之后,只是yarn ,并没有build ,可能是这个原因,接下来停服务,单独build hzro-front
yarn run build:ms hzero-front
Done in 98.76s.
再次测试,MCP界面有了,而且企业应用库,Agent编排界面也正常了(之前hzero-front-haip 更新到1.6.0-alpha.2 但hzero-front没有build到1.12.4-alpha.11的时候打开是无内容的)

不过还是有错误:
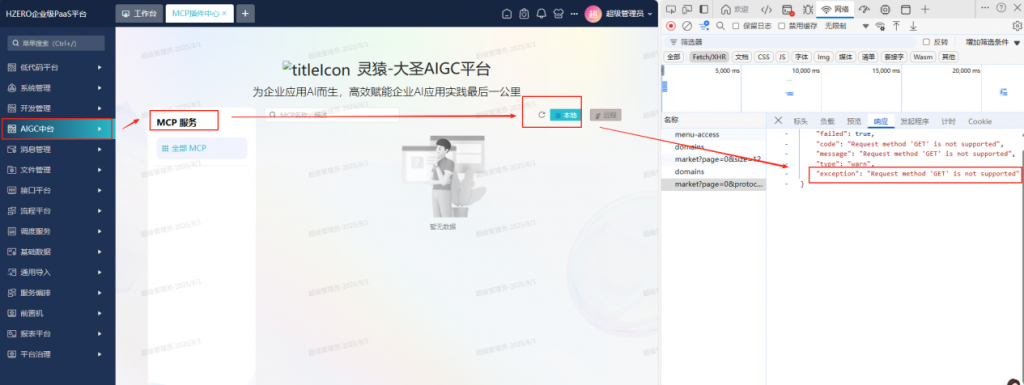
问了石云,说是在接口平台中要添加依赖:
hzero-interface服务加
<dependency>
<groupId>org.jipaas.boot</groupId>
<artifactId>jipaas-boot-interface</artifactId>
<version>1.8.0-SNAPSHOT</version>
<optional>true</optional>
</dependency>
实际上不是在hzero-interface中添加依赖,而是说:集成平台小组开发的基于hzero-interface,为MCP另外开发了微服务jipaas-interface,这个jipaas-interface已经依赖了hzero-interface, 要用MCP服务,得另外安装jipaas-interface服务,安装部署文档参考:
简单来说,就是如果你要用MCP功能,那么就要用jipaas-interface 替换hzero-interface
可以把hzero-interface的工程目录ps-interface拷贝过来,放到hzero-ipaas/project目录下,ps-interface 目录改名为ps-jipaas-interface, 修改POM文件,parent 依赖改成
<parent>
<groupId>com.hand</groupId>
<artifactId>person-jipaas-parent</artifactId>
<version>1.8.1</version>
</parent>
依赖部分,把对hzero-interface的依赖改成:
<dependency>
<groupId>org.jipaas</groupId>
<artifactId>jipaas-interface</artifactId>
<version>1.8.0.BETA</version>
</dependency>
其他不变,另外jipaas-interface中增加了对license 的依赖,启动脚本命令中把agent加上。
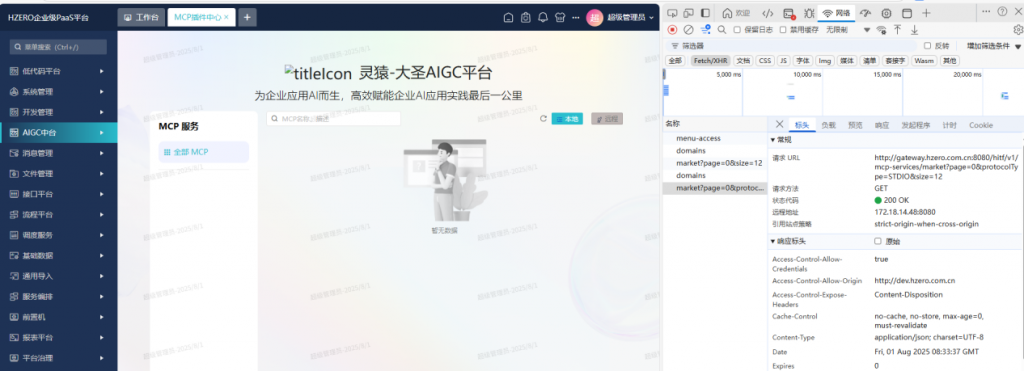
停掉原来的hzero-interface 服务,启动这个新的jipaas-interface服务,这个jipaas-interface侦听端口跟原来的hzero-interface是一样的,yml中的服务名用的也是hzero-interface , 路由前缀也没变hitf , 所以跟原来用hzero-interface是一样的,基本是无感替换。
服务替换启动后再测试:就OK了

问题解决。
3、新建模型对接,测试报错(Nginx配置)
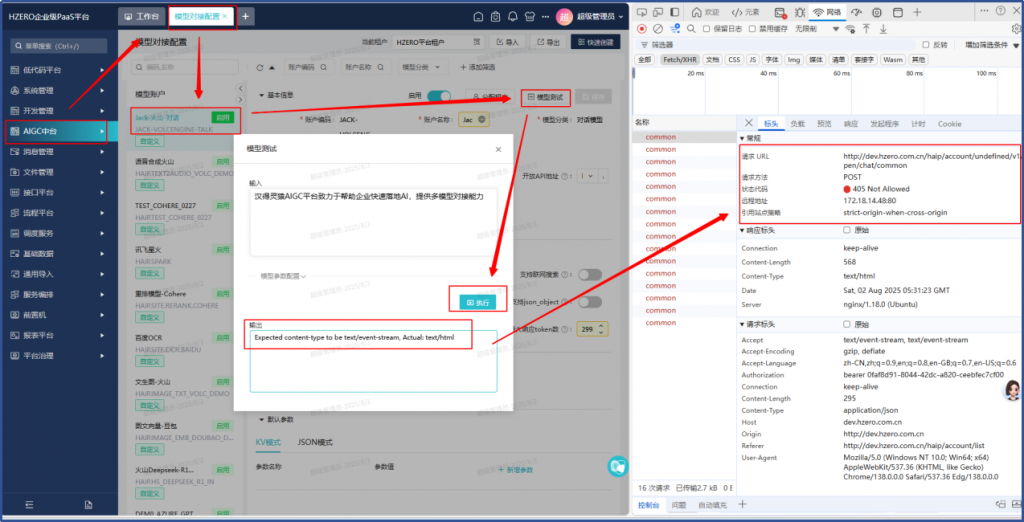
新建一个模型对接,测试时报错,看网络是api调用被限制了。
看调用地址没有走网关,为什么没走网关,要看下前端逻辑,点发起程序,搜索关键字v1/open
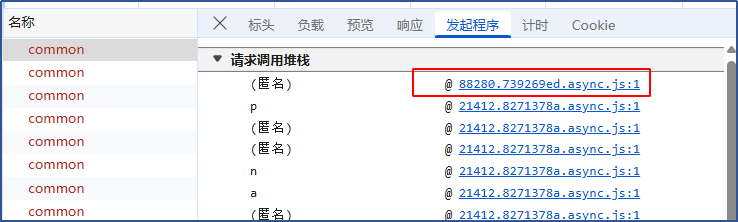
发现有些地方,在这个地址前面要拼接变量AIGC_HOST
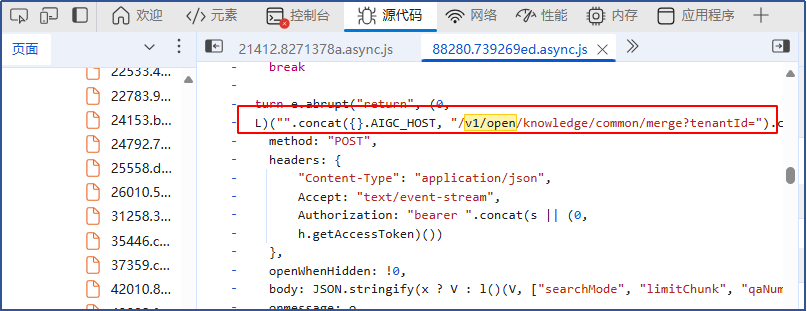
在前端 dist 目录下的index.htm中这个变量还没有被设置替换:
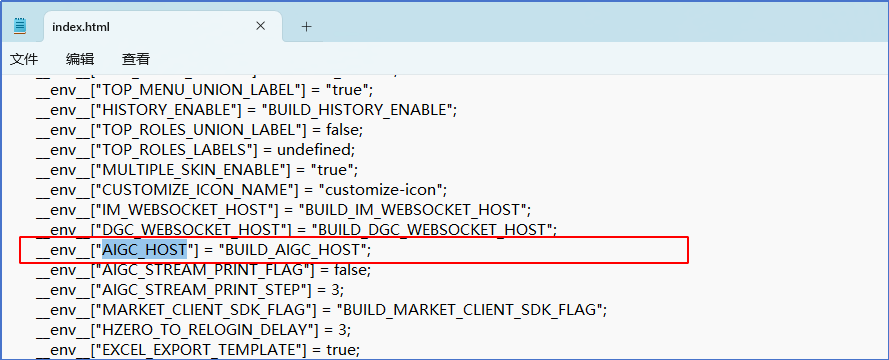
在开放平台文档搜索 AIGC_HOST , 找到如下说明:

看起来是部署问题,我们在前端dist中还没有做BUILD_AIGC_HOST的替换
文档只是举例,实际应该替换成什么地址呢?
EUREKA中可以看到hzero-aip-app服务的地址:

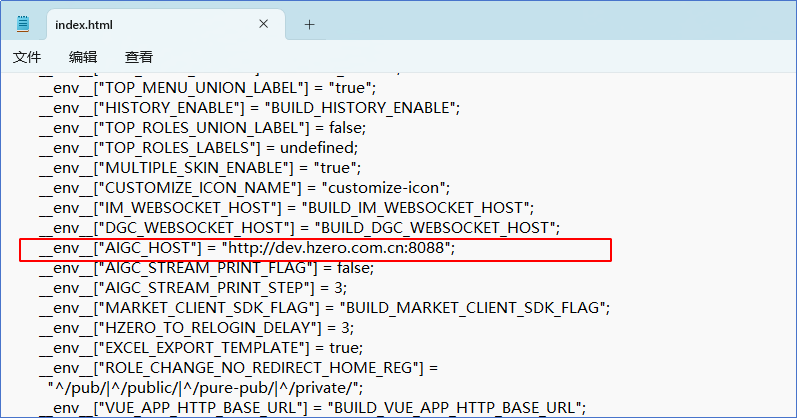
那就取这个地址试试看: 更改 index.html中的变量,保存;
然后清除浏览器历史记录,重新登录,发现还是有问题,没办法,只能再试试全局替换
全局替换后清除浏览器数据再测试,问题依旧,再仔细看代码,发现很多地方是跟HZERO_HAIP变量链接的。
查开放平台文档,只有一处地方提到:是23年新增的一个变量;

突然思考:是否搞错问题方向了:
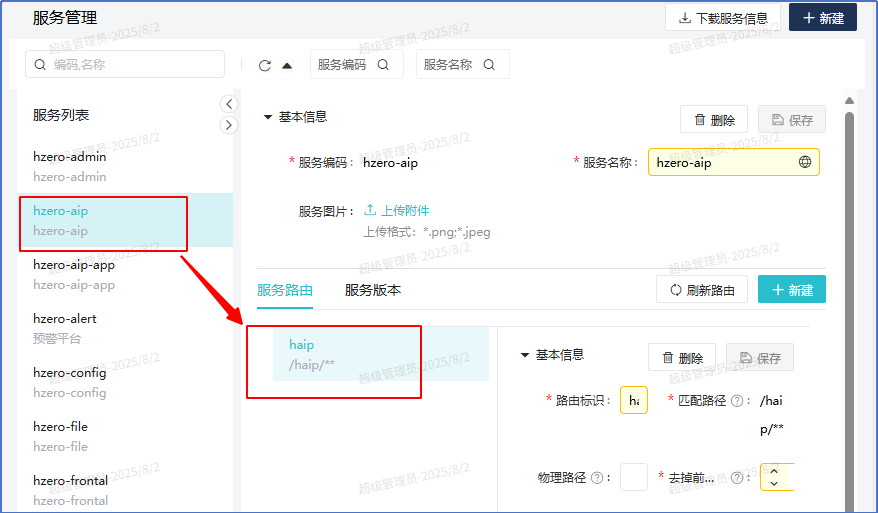
路由前缀haip是 hzero-aip server的服务路由,也就是这里调用的路由不是hzero-aip-app的路由,实际上hzero-aip-app是没有路由前缀的。
但是开放平台文档明确这是hzero-aip-app 服务中的API:

并且文档也明确了:
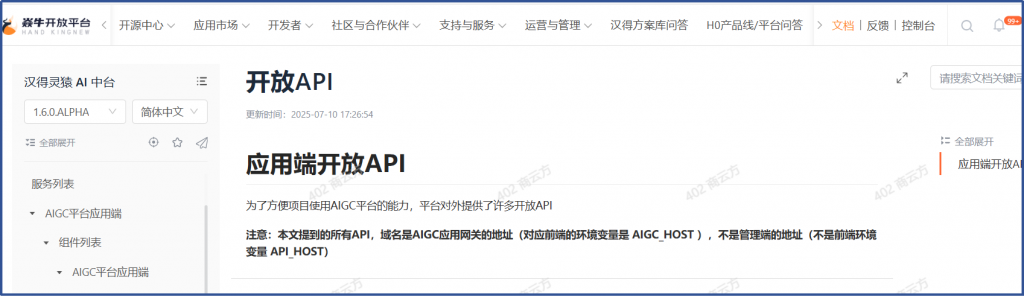
所以,调用这种hzero-aip-app服务中的API前面的地址不是网关地址,是正常的。
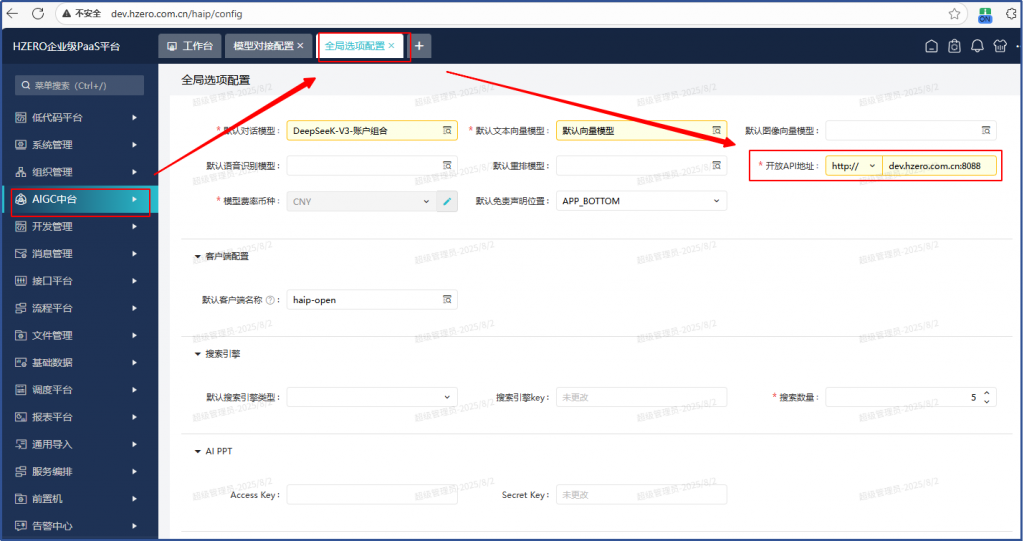
切换到租户管理员角色,可以在AIGC中台的通用配置中看到全局配置的菜单,开放平台AIGC中台全局配置说明文档中说:开放API地址就是hzero-aip-app服务的对外暴露地址
把这个地址配上,重新登录,测试新建的火山DeepSeek账户,问题依旧。
在文档中看到这么一段:就是配置AIGCapp的地址,做反向代理到hzero-aip-app对外暴露的服务网址,想着设置AIGC_HOST 变量以及这个全局配置的地方要提供的地址都是为了发布AI应用供外部页面嵌入或者直接外部访问时要用的地址。跟我们遇到的账户配置测试时发现的错误没有关系。
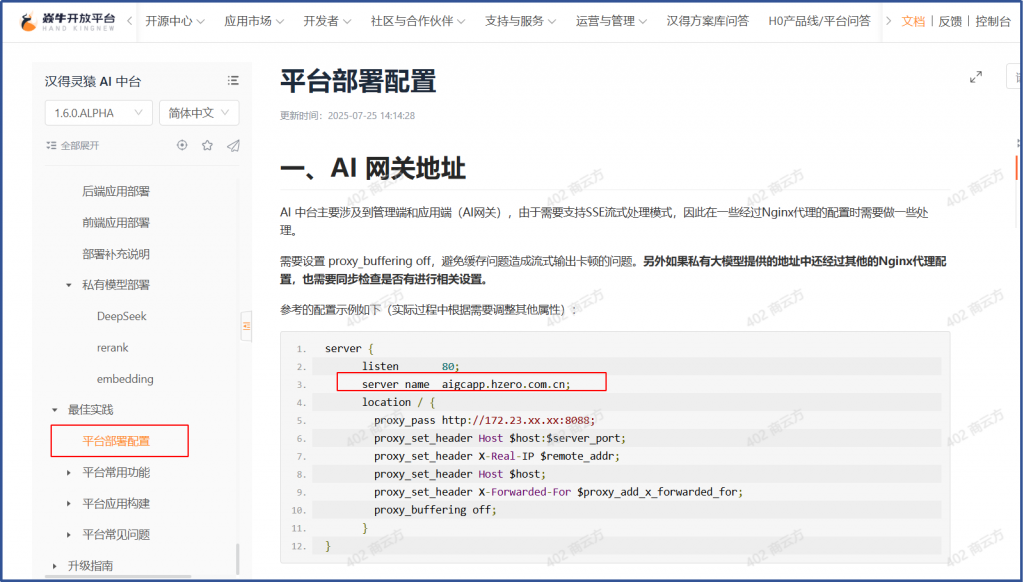
按照最佳实践做配置,windows, linux的host文件中都添加一条
172.18.14.48 aigc.hzero.com.cn #AI服务网关地址
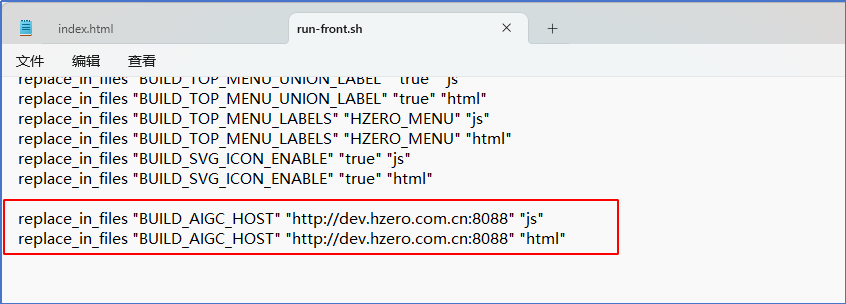
run-front.sh中改成:
replace_in_files “BUILD_AIGC_HOST” “http://aigc.hzero.com.cn” “js”
replace_in_files “BUILD_AIGC_HOST” “http://aigc.hzero.com.cn” “html”
AIGC中台的通用设置的全局配置中的开放API地址也改成http://aigc.hzero.com.cn
Nginx中反向代理按文档配置;
Server_name aigc.hzero.com.cn
Proxy_pass http://127.0.0.1:8088
nginx主配置:
/etc/nginx/nginx.conf
nginx站点配置:
/etc/nginx/sites-available/
先备份nginx配置:
cd /etc/nginx
cp nginx.conf nginx.conf.bak20250802
cd sites-available
cp default default.bak.20250802
然后修改default , 然后重启nginx , 然后再次运行 /d02/hzero/front/front/apply_update_to_runtime_env.sh
这么做当然是没有解决 新建模型账户测试出错的问题,那个问题,估计是前端程序写得有问题。
跟前端架构组沟通了下,分析过程如下:
查找问题:
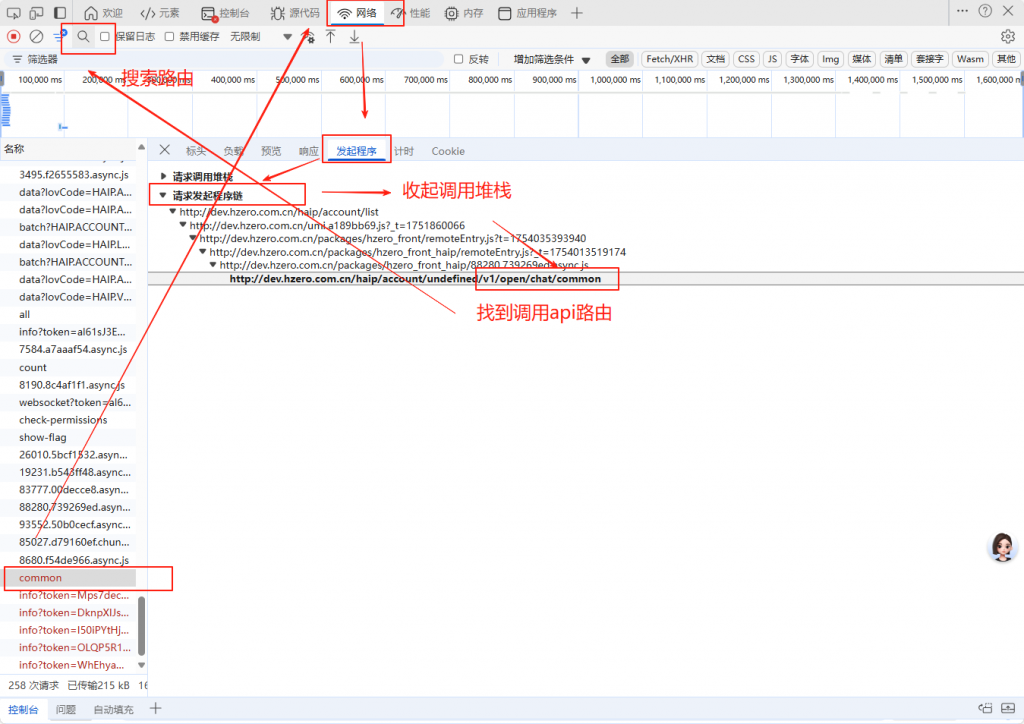
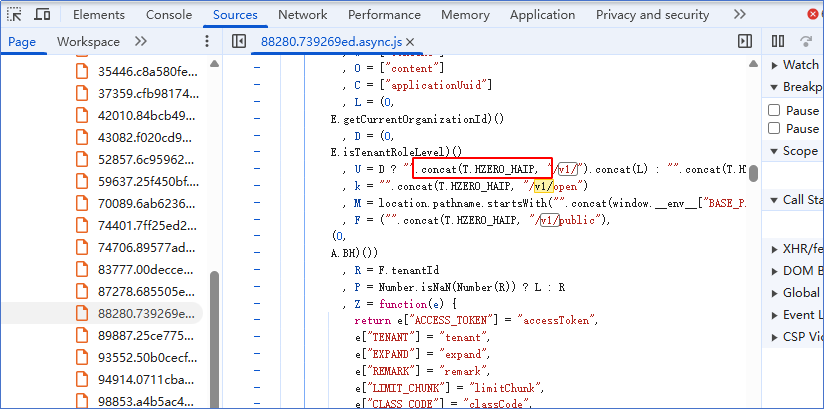
可以看到前端拼接路由的逻辑:
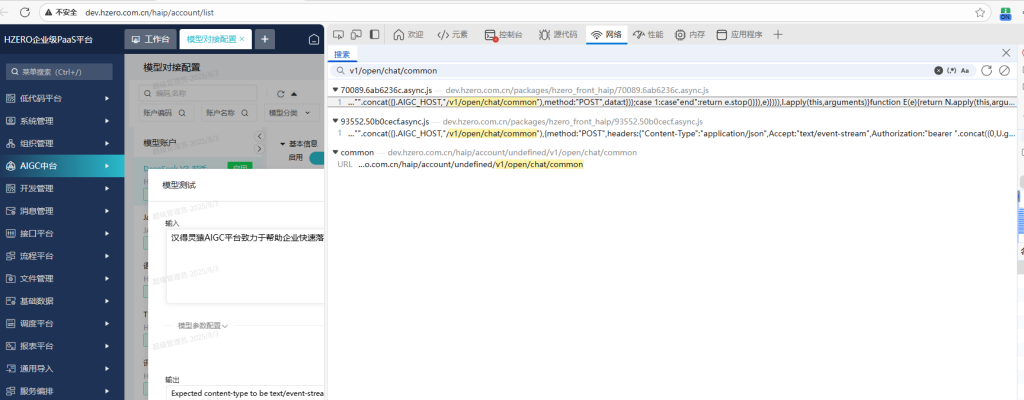
发现这里有问题,正常应该是:
下面这样从环境变量_env_ 获取”AIGC_HOST” 变量的值,但这里是{}空的,表示没有从_env_环境变量取值,可能是缺失了AIGC_HOST环境变量的定义;
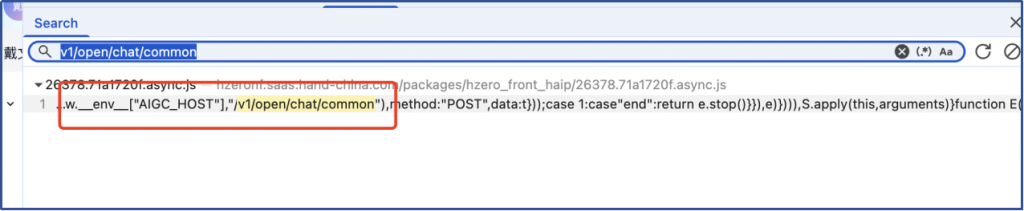
查前端工程文件中的config目录下的congfig.ts 和config.prod.ts 发现缺失没有AIGC_HOST变量的定义。
解决方案:
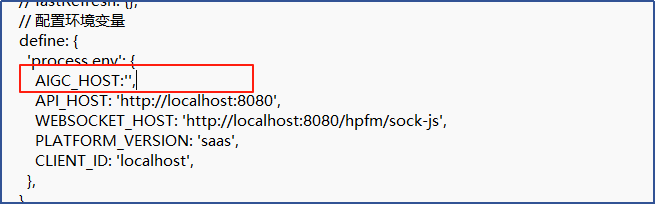
在配置文件中加上AIGC_HOST变量的定义:
Config.ts 加上:
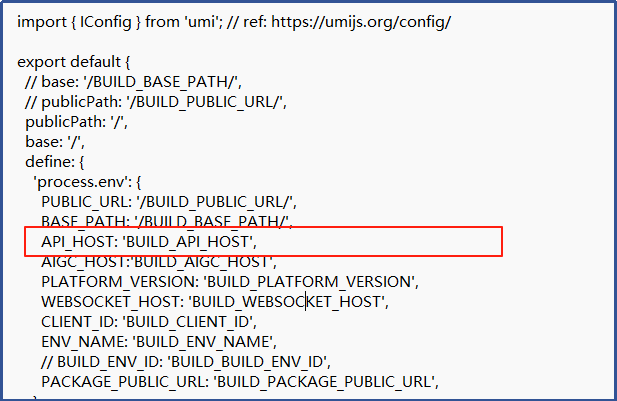
Congfig.prod.ts 加上:
然后重新yarn, yarn build:ms , apply_update_to_runtime_env.sh
yarn run build:ms hzero-front-haip
经测试已经OK了:
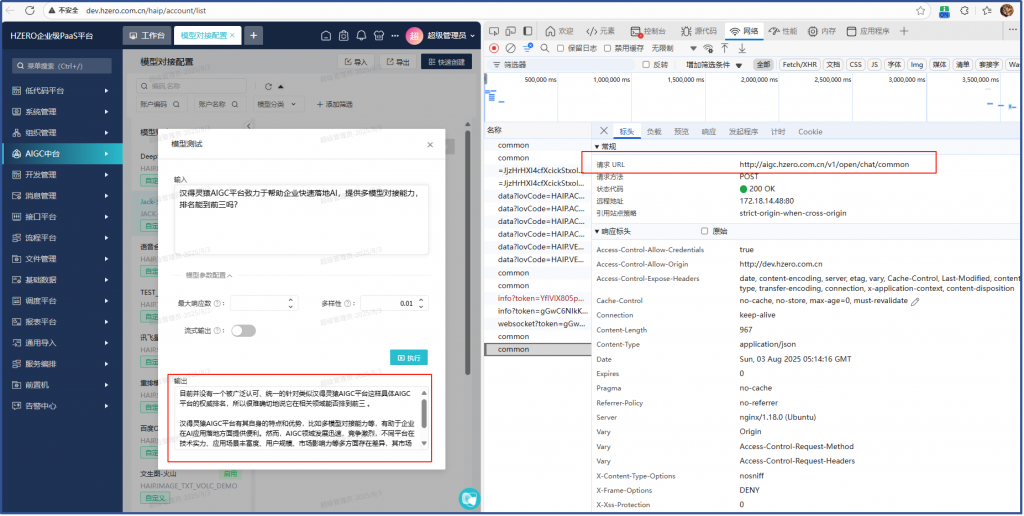
问题解决。
2、向量模型 ES的链接测试报错
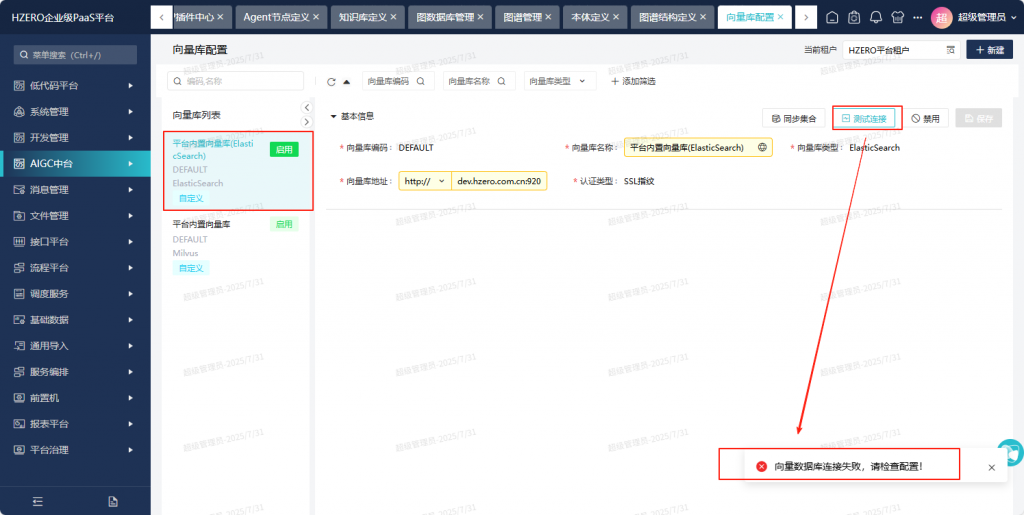
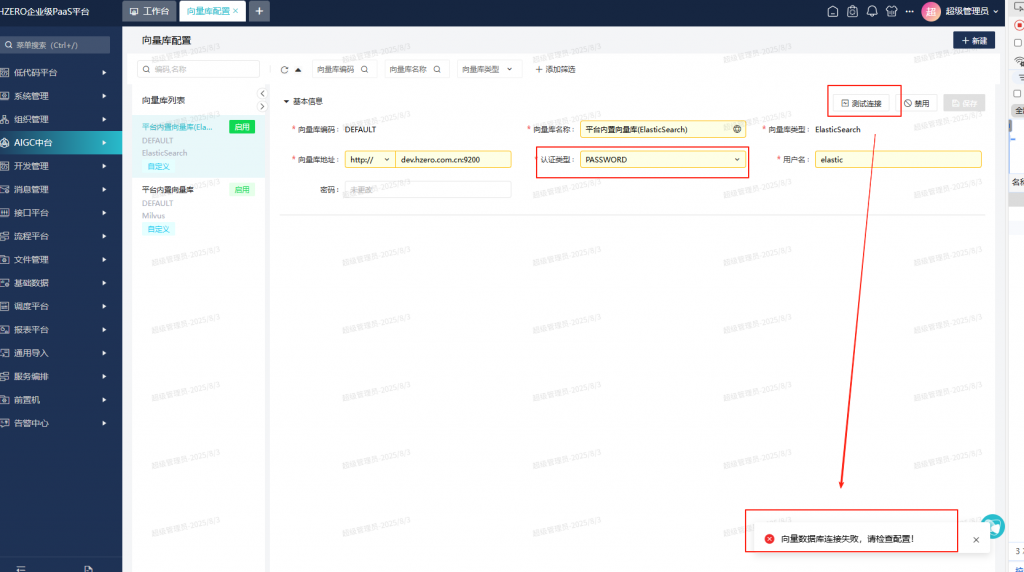
ES服务的测试链接报错,刚开始是前端版本太低,没有密码认证选项。后来升级的1.6.0.ALPHA.2 版本就有了密码认证选项了,但就算输入正确的用户名密码依然报错。
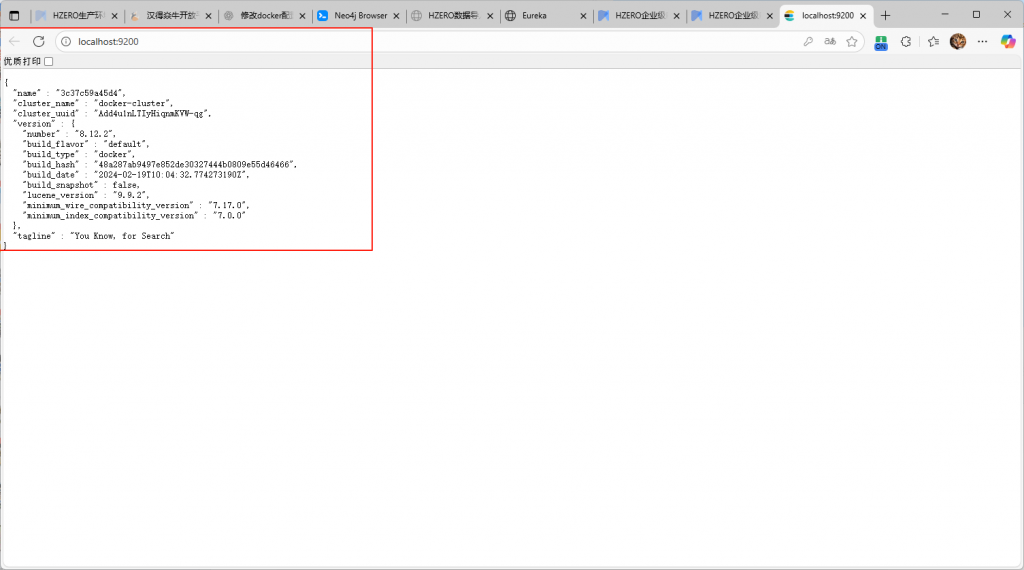
服务错误日志中显示后端服务的版本还是1.6.0.ALPHA.1.15的。
at org.hzero.aip.app.service.impl.VectorDatabaseServiceImpl.testConnection(VectorDatabaseServiceImpl.java:155) ~[hzero-aip-server-1.6.0.ALPHA.1.15.jar!/:1.6.0.ALPHA.1.15]
升级到1.6.0.ALPHA.2 再试, 依然有问题。
跟姜州沟通,说是要升级:
后端更新到新版本
hzero-aip-server 1.6.0.ALPHA.2.7
hzero-aip-app 1.6.0.ALPHA.2.7
升级后再测试,OK了:

问题解决。
3、新建火山图文向量模型对接,测试时报400 badrequest 错误
先以租户管理员角色,进开发管理/值集配置,搜索 HAIP.ACCOUNT_TYPE_MODEL 添加火山新的图文向量模型ID
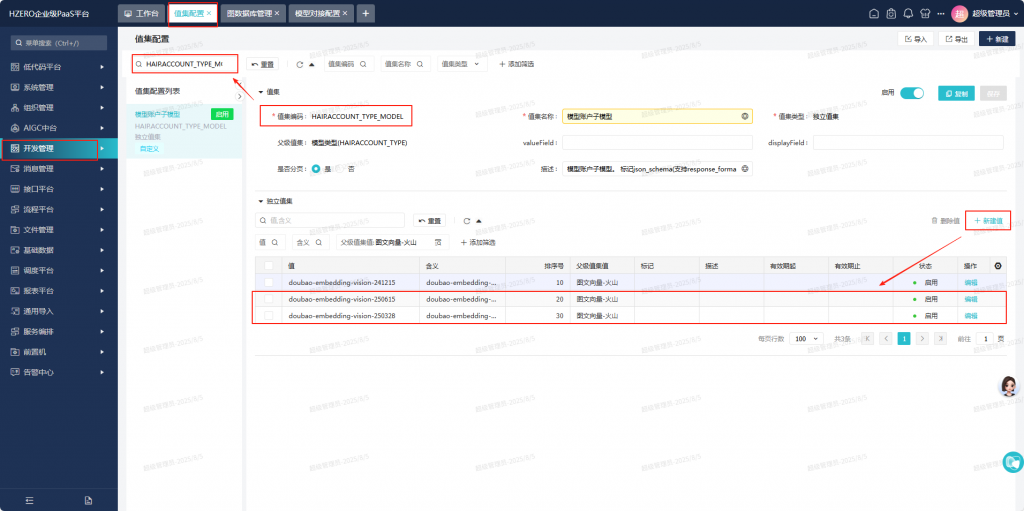
然后新建一个模型对接配置:Jack-火山-向量模型-图文,选择刚才添加的模型ID,API-KEY 是确认OK的。然后进行测试,出现这个错误,之前火山的文本模型deepseek-V3配置到这个平台测试是OK的,说明联通火山的模型服务没有问题,看起来是h0自己的图形附件处理过程有问题。
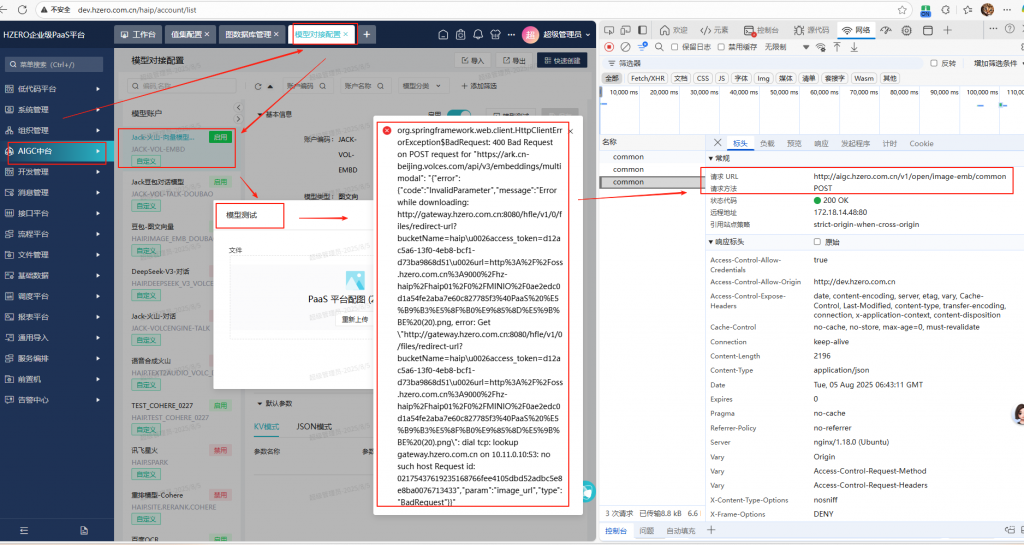
看起来是调用hzero-aip-app 服务在处理附件时出现错误
看后台日志,好像是hzero-aip-app 把图片附件的地址传给火山方舟,火山方舟根据这个地址下载图片的时候找不到图片链接域名对应主机就报错了,因为我们用的是虚拟机,这个域名也是自己在本机host文件中设置的,我们的虚拟机能访问外网,但外网是访问不了我们的虚拟机内网的,所以出现这种情况?
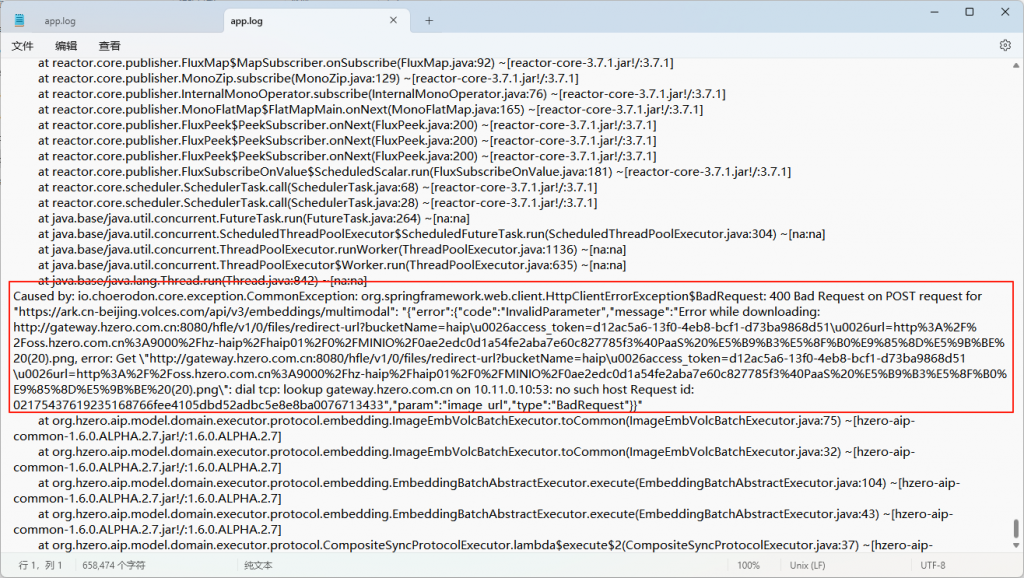
#question4-embding
4、Docker 安装环境问题:个人问答应用,上传文件,向量化解析时发生错误:
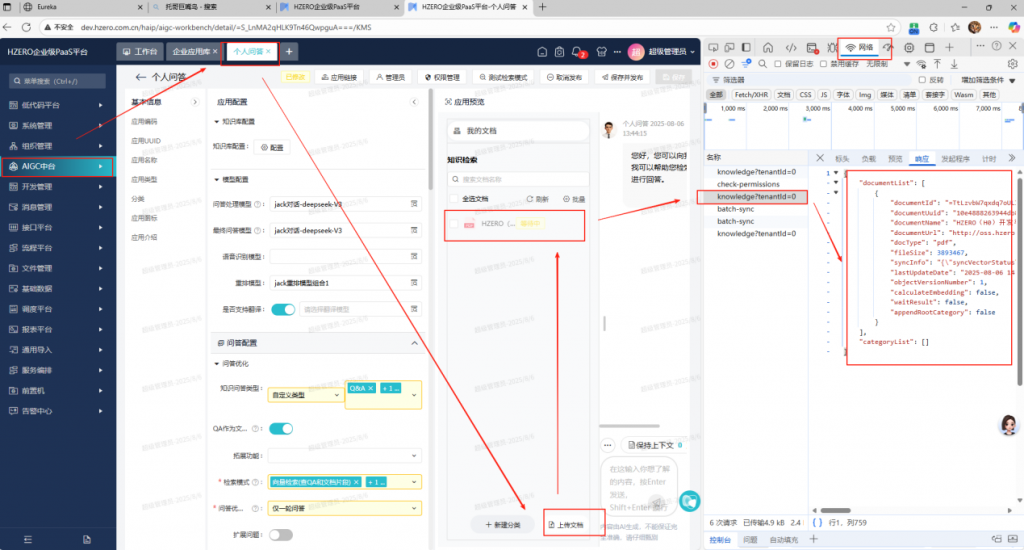
从错误反馈看是hzero-aip-server 中调用HKMS链接milvus时发生错误:
http://gateway.hzero.com.cn:8080/haip/v1/open/documents/personal/knowledge?tenantId=0
调用HKMS执行文件切片时发生错误:处理失败:<MilvusException: (code=2, message=Fail connecting to server on dev.hzero.com.cn:19530, illegal connection params or server unavailable)>\”}”
分析:
先看milvus本身的状态是OK的:
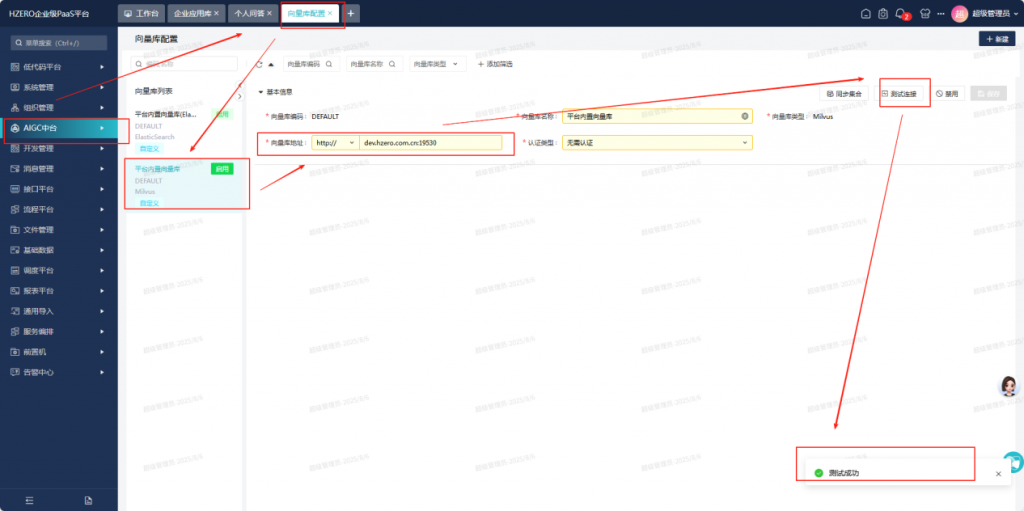
再看HKMS的日志:
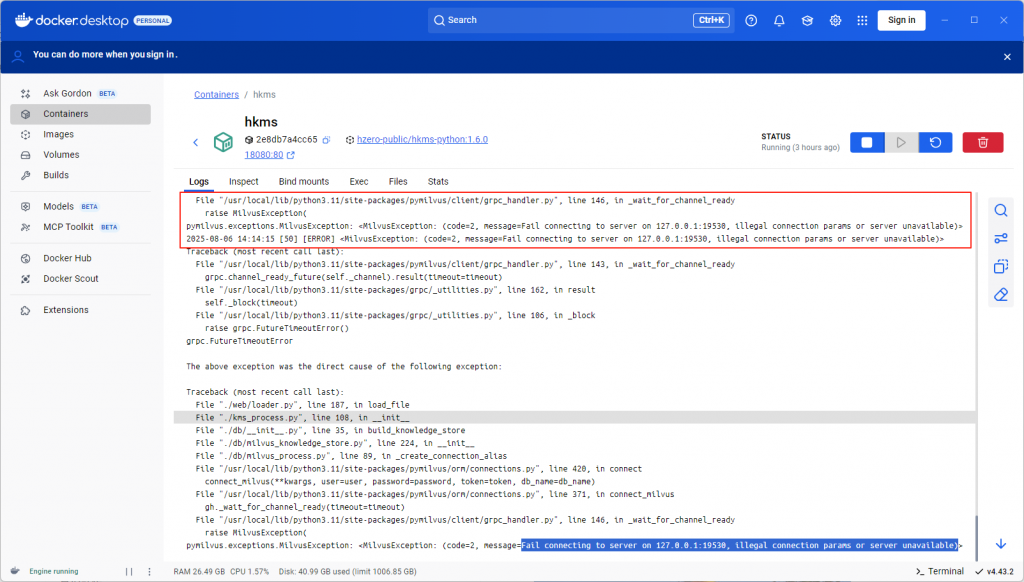
看起来是HKMS服务自己链接Milvus失败,但为什么呢?
看hkmk docker容器的日志:
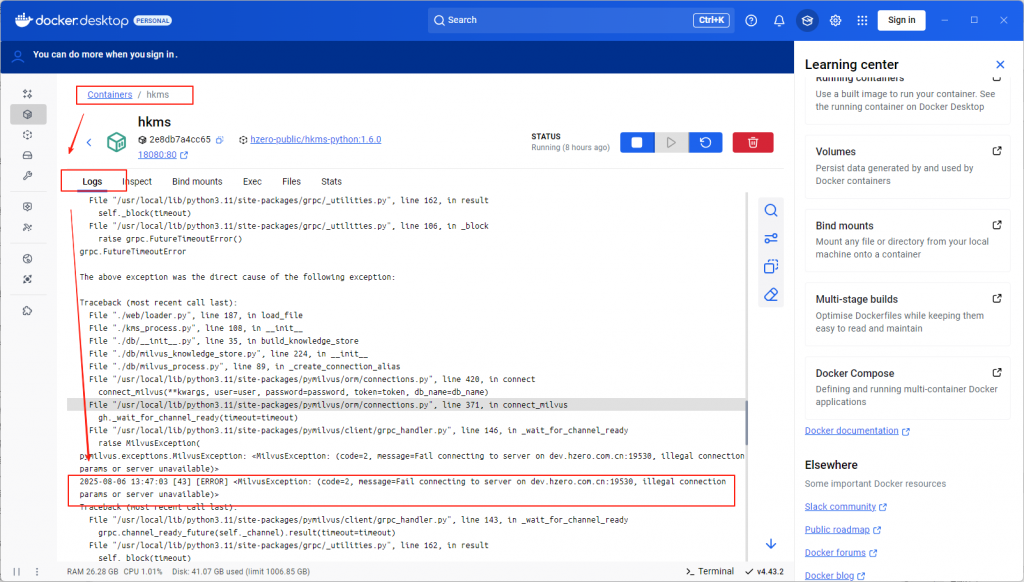
问题是HKMS docker容器链接milvus服务失败。在容器内ping也ping不通

由于WSL网络中,HKMS使用docker-compose.yml配置中指定网络:aigc, 这个aigc网络的网关是windows主机上的一张虚拟网卡地址;windows可以ping通这个地址,但linux虚拟机ping不同这个地址,所以liunx也就不能跟HKMS容器实现网络互通。而milvus容器使用脚本启动,没有指定网络,它通过端口映射,可以通过linux虚拟机的IP访问到服务,但HKMS与虚拟机网络不互通,因此HKMS访问不到milvus.
解决方案有两个:
1、docker-compose.yml中把HKMS的网络模式改成host模式,因为host模式下,端口映射不起作用,所以就要在容器外的nginx的侦听端口从80直接改成18080,这样hkms应该就可以访问到linux host机的IP地址了。缺点是HKMS原来是bridge模式,并且加入了aigc网络,所以跟neo4j, es, hpye这几个容器之间可以通过容器名直接联通相互访问。但改成host模式之后就不能相互访问了。 我估计hkms服务本身也没有这种设计和需求,所以应该没关系。
2、把milvus从命令启动模式改成 yml配置使用docker-compose 启动的方式,并且在yml配置中加入网络aigc, 这样milvus就能跟hkms在同一网络中了。在dokcer容器内,同一网络的其他容器可以通过容器的服务名访问,那我们在aigc的向量库配置的地方,测试链接地址直接写milvus的docker容器名,然后在liunx虚拟机的host文件中把这个容器名的解析加上,这样hzero-aip-server服务可以访问到这个milvus , 而且链接串传给hkms容器内的服务后,HKMS也可以访问到milvus .
感觉第一种方案简单一些,先试试。
经测试不行,hzero-aip-server 无法链接127.0.0.1:18080端口,访问被拒绝,豆包解释:通常与容器内 Nginx 未正常启动、配置未生效或WSL 环境的网络特殊性有关。关键原因:WSL 环境中 host 模式的端口绑定在 Docker 虚拟机,而非 WSL 发行版。所以这种方案否决掉。
它不在aigc这个网络中,与HKMS不能互通,而且HKMS容器内也访问不了linux虚拟机的IP地址。
尝试第2种方案,HKMS可以链接到milvus,但另一个错误又出现了,HKMS访问附件是链接失败,因为附件是要链接mino服务,它也是访问不到的,但mino服务没有用容器,是直接安装在linux 虚拟机上的,没法用刚才的办法解决。所以这种方案也否决掉。
为了测试容器间的网络互通性,需要在容器内安装ping命令工具:
apt-get update && apt-get install -y iputils-ping
导致这一切问题的根源在于我使用了windows docker desktop, 虽然能共享docker,不用在虚拟机中另外安装docker ,但问题就是创建的aigc网络也没有在我的Linux虚拟机中生成虚拟网卡,而是在windows docker desktop自己的WSL中去生成桥接的aigc网络网卡了,这就导致我的linux虚拟机与aigc网络不能互通。
所以终极解决方案是
3、在linux虚拟机中单独安装docker 和docker compose 插件,问下豆包“ubuntu 22.04里面如何安装docker 和docker compose”,豆包会给出详细步骤,按指导安装很快的。
在我的wsl虚拟机单独安装docker软件后再次启动这些docker容器,这次我从docker容器里面就可以ping通linux虚拟机的IP地址了,这样网络就通了。
再次测试:发现还是报错,这次是HKMS 的错误
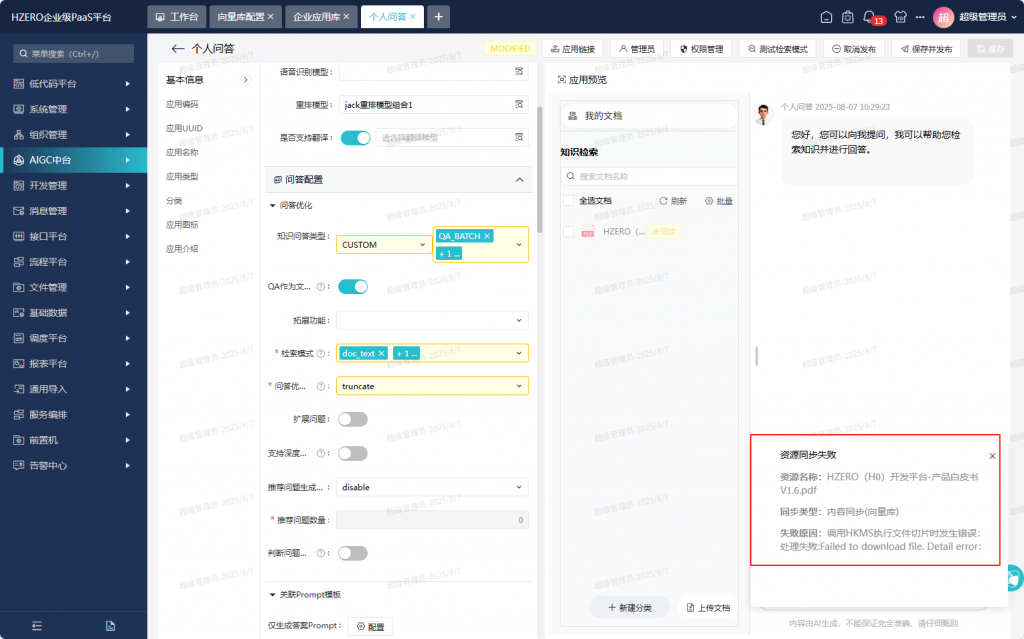
docker logs hkms 看容器日志:
Traceback (most recent call last):
File “./kms_process.py”, line 458, in process_file
File “./loader/doc_loader.py”, line 264, in load_document_from_url
File “./loader/doc_loader.py”, line 201, in download_from_url
Exception: Failed to download file. Detail error: <urlopen error [Errno -2] Name or service not known>
2025-08-07 10:29:32 [46] [INFO] process_file存在错误:Failed to download file. Detail error: <urlopen error [Errno -2] Name or service not known>,file_url=http://oss.hzero.com.cn:9000/hz-haip/haip01/0/MINIO/0a02eb2273824e11bbecd18dc5a60006%40HZERO%EF%BC%88H0%EF%BC%89%E5%BC%80%E5%8F%91%E5%B9%B3%E5%8F%B0-%E4%BA%A7%E5%93%81%E7%99%BD%E7%9A%AE%E4%B9%A6V1.6.pdf?response-content-disposition=attachment%3Bfilename%3DHZERO%25EF%25BC%2588H0%25EF%25BC%2589%25E5%25BC%2580%25E5%258F%2591%25E5%25B9%25B3%25E5%258F%25B0-%25E4%25BA%25A7%25E5%2593%2581%25E7%2599%25BD%25E7%259A%25AE%25E4%25B9%25A6V1.6.pdf&response-cache-control=must-revalidate%2C%20post-check%3D0%2C%20pre-check%3D0&response-expires=1754533773094&X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=hzero.admin%2F20250807%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20250807T022932Z&X-Amz-Expires=300&X-Amz-SignedHeaders=host&X-Amz-Signature=b2c4f279f63370d726cd97eb0fe4e0966cf2a237e181b2daf5cd38025d93e803
2025-08-07 10:29:32 [46] [ERROR] Failed to download file. Detail error: <urlopen error [Errno -2] Name or service not known>
看起来是HKMS 服务下载文件不成功, 我们进入容器内,ping下这个网址oss.hzero.com.cn
docker exec -it hkms bash
root@406f2c57c70c:~/hkms# ping oss.hzero.com.cn
ping: oss.hzero.com.cn: Name or service not known
PING 172.18.14.48
(172.18.14.48) 56(84) bytes of data.
64 bytes from 172.18.14.48: icmp_seq=1 ttl=64 time=0.059 ms
64 bytes from 172.18.14.48: icmp_seq=2 ttl=64 time=0.048 ms
我们在linux虚拟机的/etc/hosts文件中配置oss.hzero.com.cn 域名指向172.18.14.48 ,可惜容器内不能自动解析主机的hosts
在HKMS容器的yml文件中添加extra_hosts:
services:
hkms:
container_name: hkms
image: registry.hand-china.com/hzero-public/hkms-python:1.6.0
extra_hosts:
– “oss.hzero.com.cn:172.18.14.48″ # 格式:”主机名:IP地址”
– “dev.hzero.com.cn:172.18.14.48”
然后重启容器
再进容器测试联通性,OK了:
root@24052bb231d7:~/hkms# ping oss.hzero.com.cn
PING oss.hzero.com.cn (172.18.14.48) 56(84) bytes of data.
64 bytes from dev.hzero.com.cn (172.18.14.48): icmp_seq=1 ttl=64 time=7.34 ms
64 bytes from dev.hzero.com.cn (172.18.14.48): icmp_seq=2 ttl=64 time=0.034 ms
再到界面测试:
刚才那个错误没了,但出现另一个错误:
资源同步失败
资源名称:HZERO(H0)开发平台-产品白皮书V1.6.pdf
同步类型:内容同步(向量库)
失败原因:调用HKMS执行文件切片时发生错误:处理失败:T0_KMS_DOCUMENT
docker logs hkms 容器日志中更详细的日志是: 缺集合:T0_KMS_DOCUMENT
Traceback (most recent call last):
db.exception.KnowledgeCollectionNotExists: T0_KMS_DOCUMENT
2025-08-07 11:05:42 [41] [INFO] process_file存在错误:T0_KMS_DOCUMENT,file_url=http://oss.hzero.com.cn:9000/hz-haip/haip01/0/MINIO/0a02eb2273824e11bbecd18dc5a60006%40HZERO%2025-08-07 11:05:42 [41] [ERROR] T0_KMS_DOCUMENT
Traceback (most recent call last):
File “./db/milvus_knowledge_store.py”, line 831, in _get_collection
File “/usr/local/lib/python3.11/site-packages/pymilvus/orm/collection.py”, line 137, in __init__
raise SchemaNotReadyException(
pymilvus.exceptions.SchemaNotReadyException: <SchemaNotReadyException: (code=1, message=Collection ‘T0_KMS_DOCUMENT’ not exist, or you can pass in schema to create one.)>
但实际上是存在的:
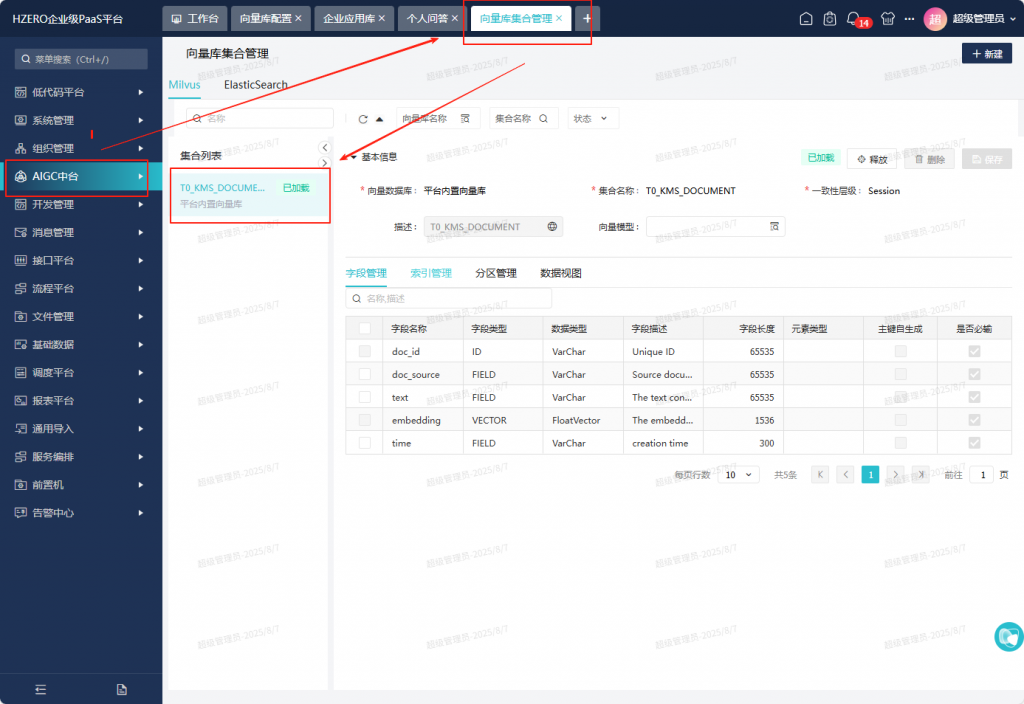
发现这里的向量模型没有配置,另外全局配置中用的也是默认向量组合,那个组合没有配置API key , 得改成我已经配置API Key得账户组合:jack多模态向量-豆包组合1
不过改成这个向量之后,保存的时候提示:向量字段的长度与模型维度不匹配,请检查相关配置
在操作界面会报错误:
资源同步失败
资源名称:HZERO(H0)开发平台-产品白皮书V1.6.pdf
同步类型:内容同步(向量库)
失败原因:调用HKMS执行文件切片时发生错误:处理失败:haip.error.hkms.milvus_error – Collection field dim is 1536, but entities field dim is 2048
重建T0_KMS_DOCUMENT集合,先释放,再删除,再新建:
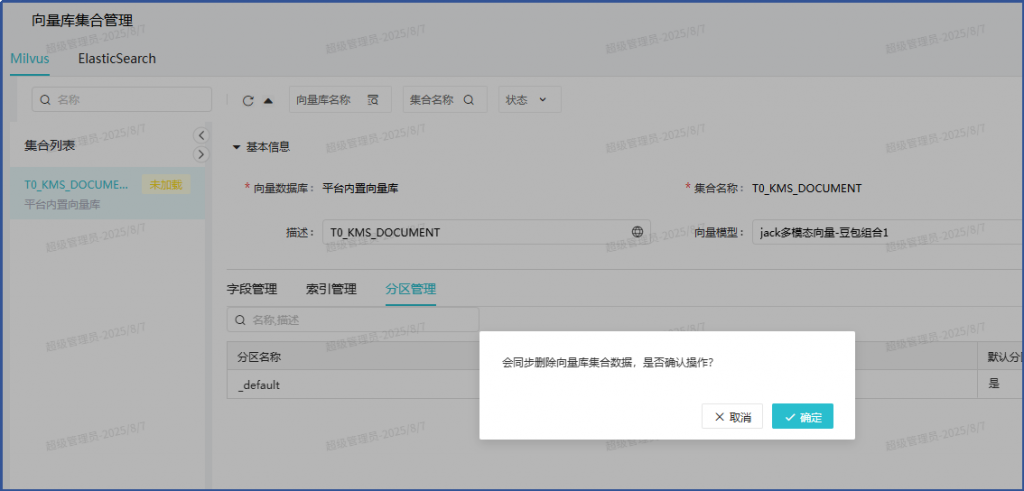
删除操作成功,再新建:
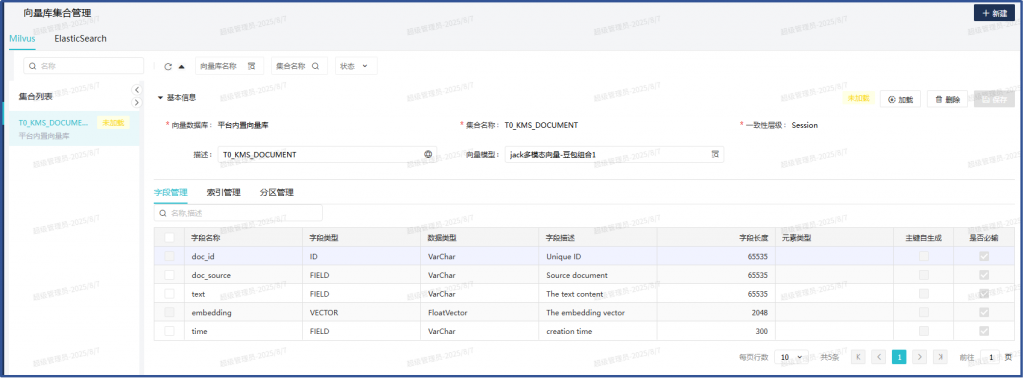
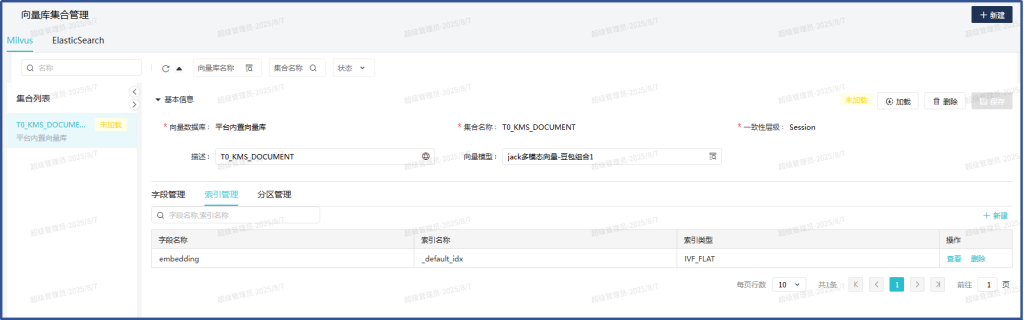
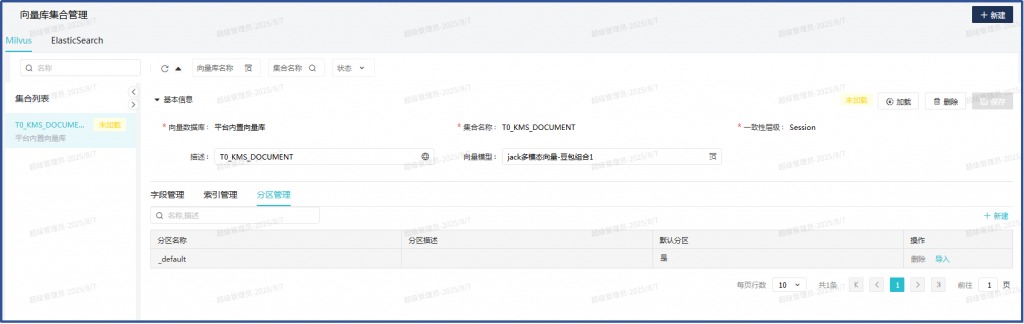
新建完成后加载:
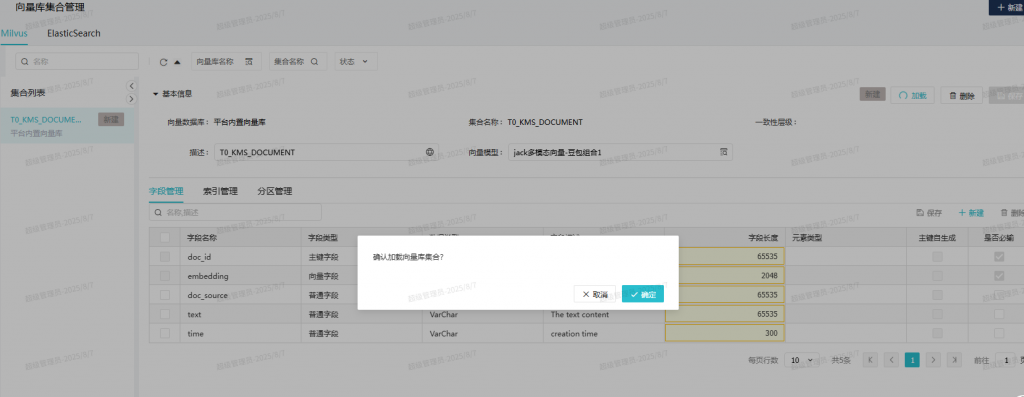
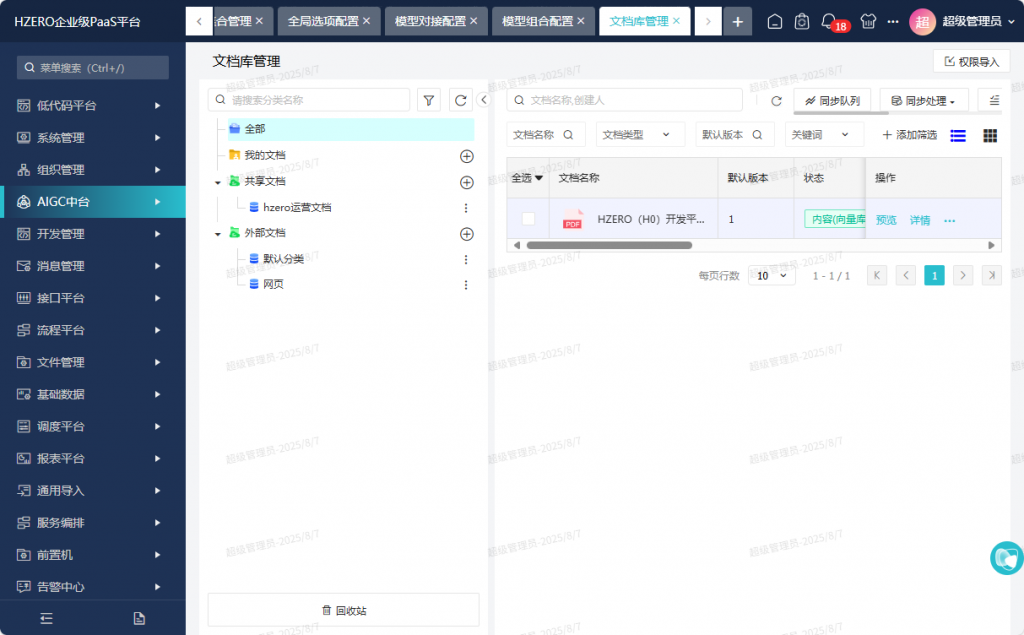
再次同步,没有报错,去文档管理看到已经同步成功了:
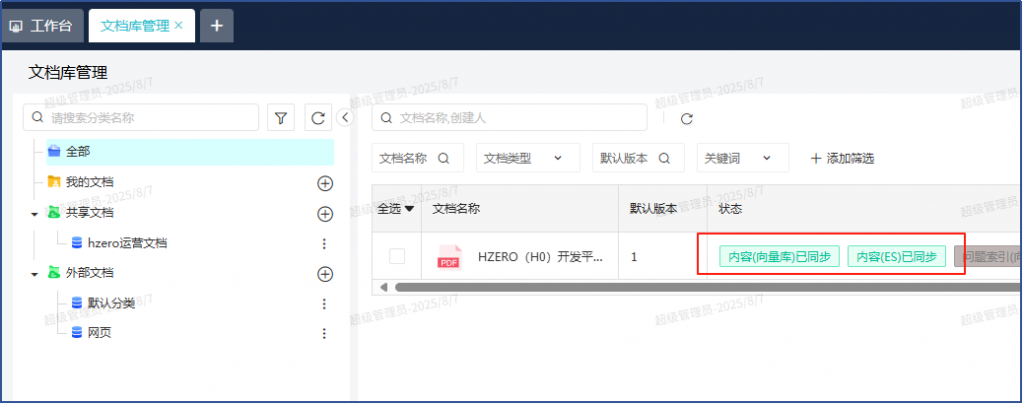
ES同步要在第三步勾选:

问题解决。
5、个应用导航的编排,点测试运行就报错,后台日志报 “: 400 BAD_REQUEST ”
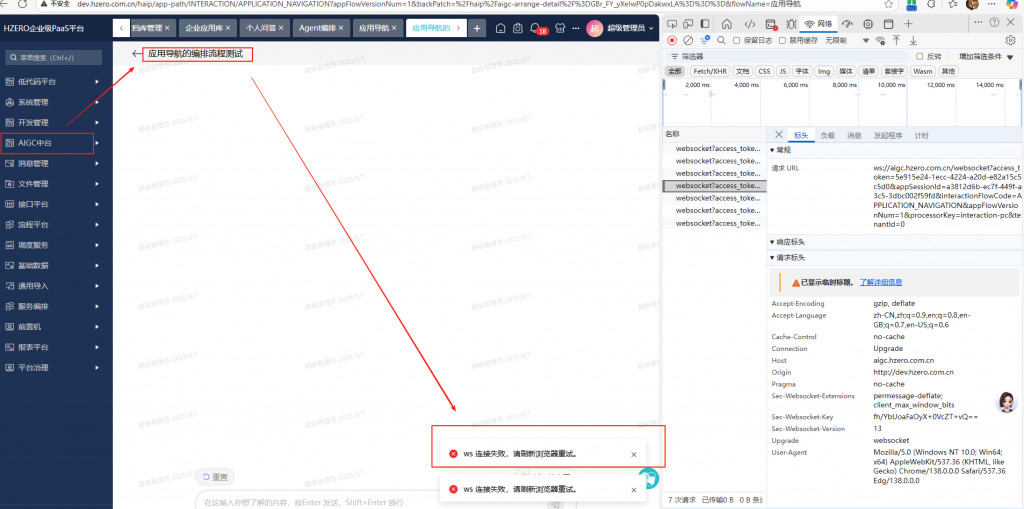
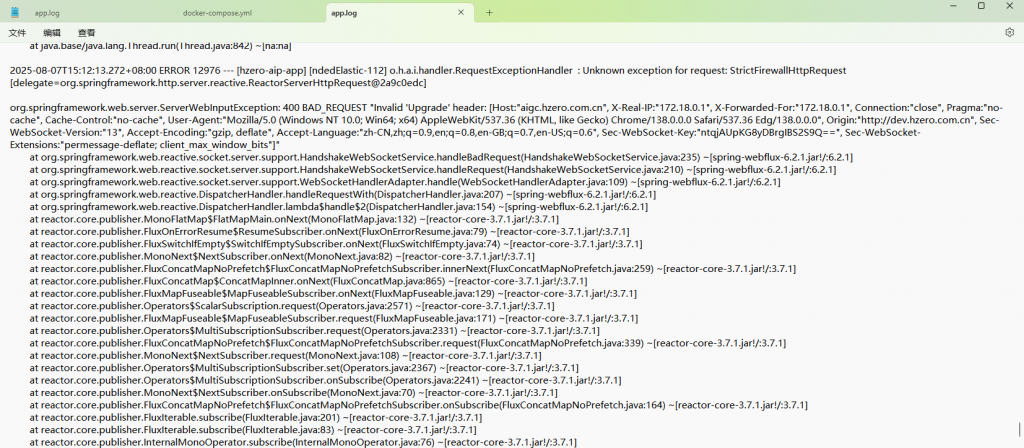
调用的地址是
ws://aigc.hzero.com.cn/websocket?access_token=5e915e24-1ecc-4224-a20d-e82a15c5c5d0&appSessionId=c537c1c4-925e-43a6-ad12-e2eba13b7a2d&interactionFlowCode=APPLICATION_NAVIGATION&appFlowVersionNum=1&processorKey=interaction-pc&tenantId=0
我看到前端环境变量 websocket_host是另一个地址:
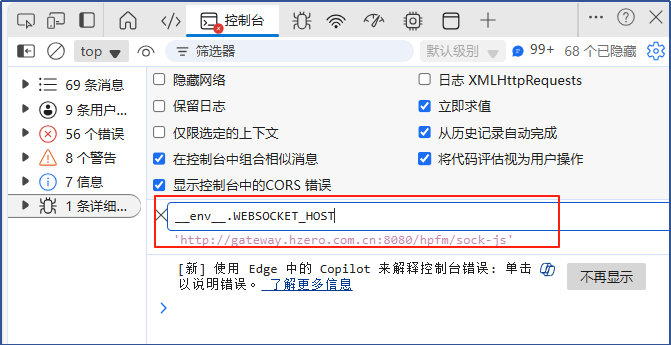
跟何博沟通了下,何博说那是平台用的WS地址,并非AI 用的WS地址,所以不影响,怀疑是Nginx反向代理设置的地方往请求头里面少加了内容,看了下nginx的反向代理配置:
# aigc.hzero.com.cn 专用服务器
server {
listen 80;
server_name aigc.hzero.com.cn;
location / {
# 改为后端服务实际IP:端口
proxy_pass http://127.0.0.1:8088; # 示例:假设后端在本机8088
proxy_set_header Host $host; # 保留一个Host配置
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_buffering off; # 按需开启/关闭(实时交互场景建议关闭)
}
}
确实没有”upgrade”这样的connection
于是就让加了两条配置:
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection “upgrade”;
加了之后重启nginx , 然后就没有那个错误了
问题解决。
6、文档管理/文件预览出错(需安装KKv):
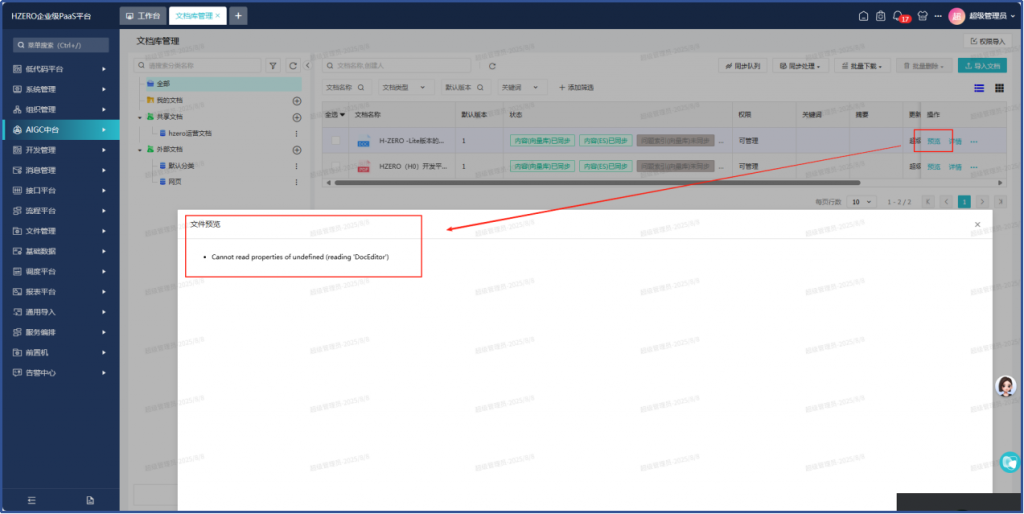
解决方案:
安装 kkfile view 或者only office服务,并配置文件服务,详情可参考开放平台/HZERO汉得企业级PaaS平台/服务列表/文件管理/组件列表/文件管理/开发者指南/文件预览配置
我们这里安装轻量一点的kkv(KKV部署指南参考文档预览 – Gitee.com)
1、先下载KKV(花90加入KKV知识星球,可以获得最新版本)
cd /d02/hzero/project/ps-file/kkv
tar -xvf kkFileView-4.4.0.tar.gz
cd ./kkFileView-4.4.0/bin
./startup.sh
2、在文件服务的POM中添加依赖:
<dependency>
<groupId>org.hzero.starter</groupId>
<artifactId>hzero-starter-fileview-core</artifactId>
</dependency>
<dependency>
<groupId>org.hzero.starter</groupId>
<artifactId>hzero-starter-fileview-kk</artifactId>
<optional>true</optional>
</dependency>
然后在文件服务的yml配置中加上下面配置
kk-version: 4 #3以下版本可不指定(版本3.x写3,版本4.x写4)
preview-type: kkFileView
kk-file-view-url: http://dev.hzero.com.cn:8012/onlinePreview # kkFileView的文件预览地址
重新构建启动文件服务
cd /d02/hzero/project/ps-file
sh run.sh
3、拷贝windows目录下的字体文件(这里拷贝字体并处理是为了解决预览时的乱码问题):
cp -r /mnt/c/windows/fonts/* /usr/share/fonts
- 执行 sudo fc-cache -fv /usr/share/fonts 后,无需重启服务器。
- 若个别应用程序未识别到新字体,重启该应用程序即可。
4、重启kkv(字体问题解决要生效,需要重启kkv)
cd /d02/hzero/project/ps-file/kkv/kkFileView-4.4.0/bin
./shutdown.sh
./startup.sh
再次测试:
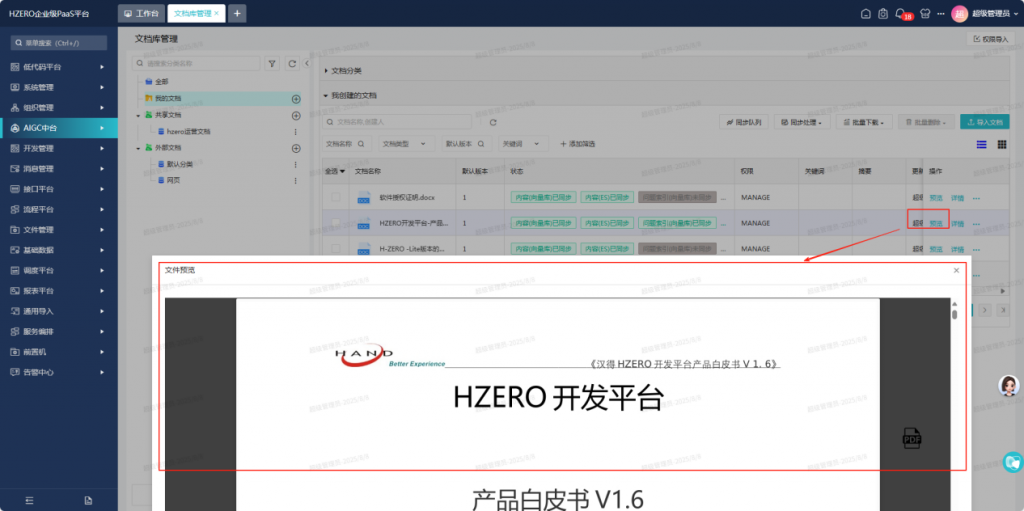
word文档预览显示正常,问题解决。
7、文档向量化时发生错误,链接不到milvus服务器,milvus服务意外关闭
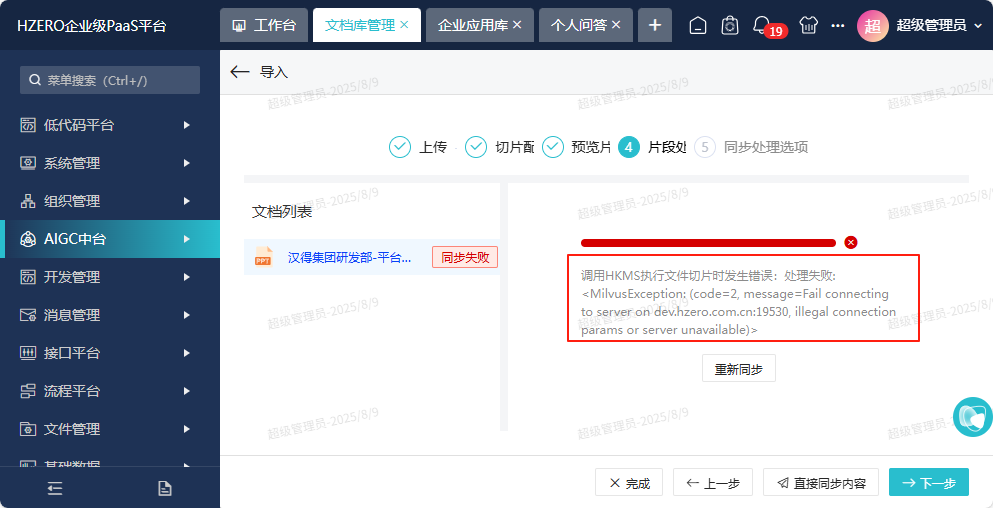
milvus在总服务启动脚本中成功启动,链接测试也OK,之前向量化操作也成功,突然出现这种情况,肯定时milvus被以外关闭了。
把milvus的日志丢给元宝,元宝猜测是能时发生OOM了,dmesg查系统日志,果然:
dmesg | grep -E ‘kill|oom|segfault|milvus’
[ 3425.898442] milvus invoked oom-killer: gfp_mask=0x1100cca(GFP_HIGHUSER_MOVABLE), order=0, oom_score_adj=0
[ 3425.900369] Memory cgroup out of memory: Killed process 3040 (milvus) total-vm:9695748kB
total-vm: 9695748 kB ≈ 9.2 GB
- 表示该进程(或容器内所有进程总和)尝试使用的虚拟内存达到了约 9.2GB
由于笔记本内存有限,我在milvus的启动脚本中设置的内存是600M,物理+交换也是600M,也就是交换分区为0, 但元宝说这只是物理内存限制,并未限制住虚拟内存。
根本原因总结:Milvus(或其所在的容器/控制组)尝试使用的内存超过了系统或 cgroup 设置的内存上限,触发了 OOM Killer,导致 Milvus 被强制终止。
解决方案:
把–Memory-swap设置到1.2G, 重启milvus
关于作者:
| 昵称:Jack.shang 档案信息:jack.shang 程序员->项目经理->技术总监->项目总监->部门总监->事业部总经理->子公司总经理->集团产品运营支持 联系方式:你可以通过syfvb@hotmail.com联系作者 点击查看Jack.shang发表过的所有文章... 本文永久链接: http://blog.retailsolution.cn/archives/4663 |
对本文的评价:
