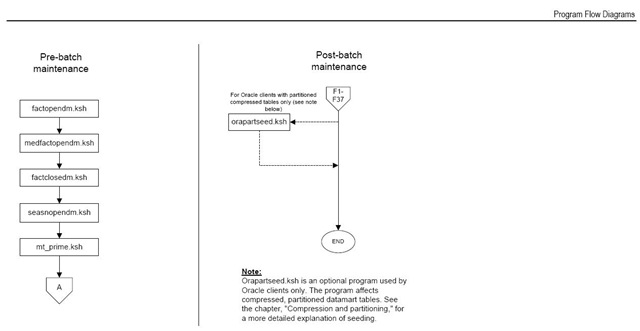
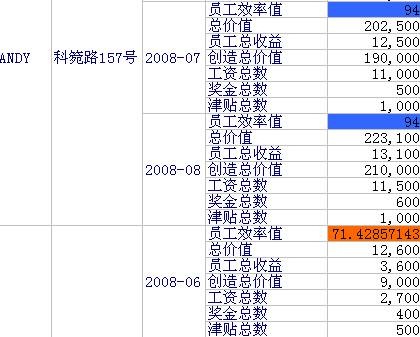
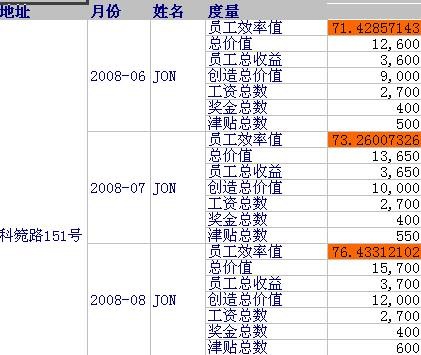
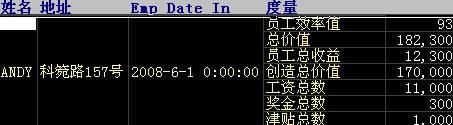
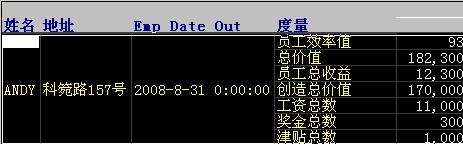
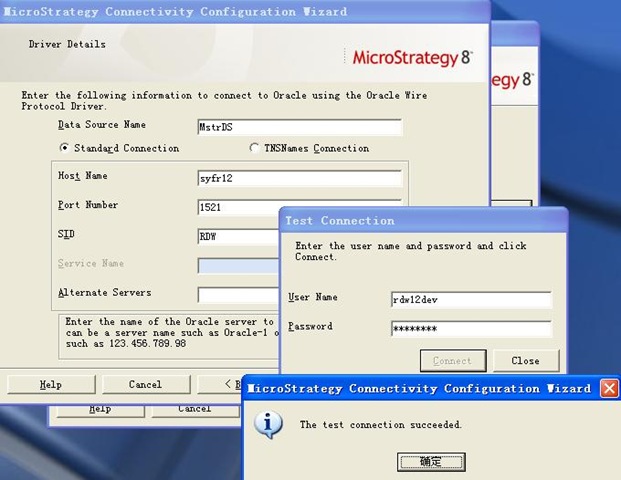
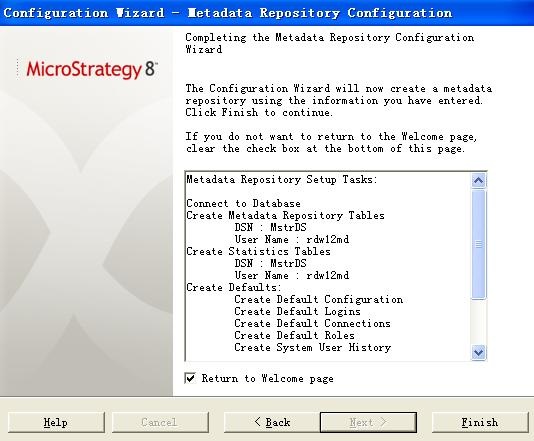
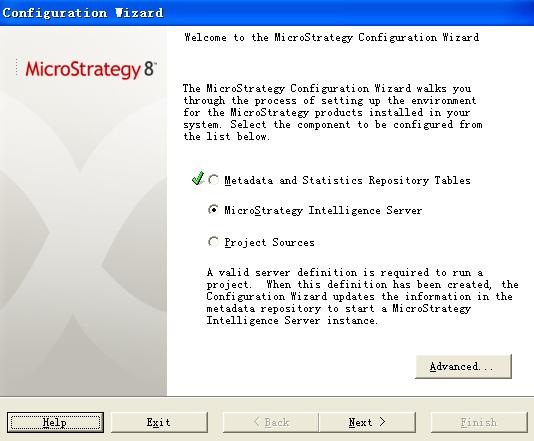
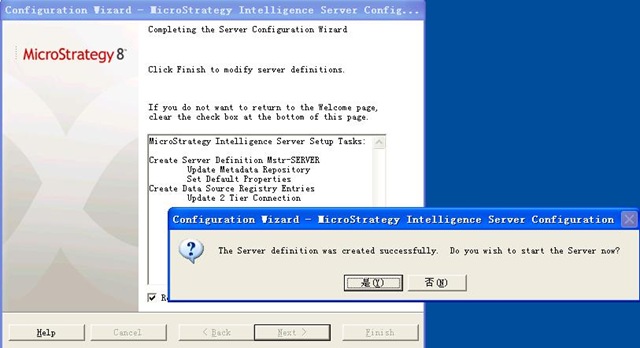
接着安装 RDW Database 的最后一步操作:
2.3.15 创建RDW时间和日期(即往 RDW 各日期基表中写入初始数据) 时出现以下问题:
一、安装 RDW Database 参考文档 rdw-120-ig-db.pdf 章节:Create Time in RDW 中有说明:
====================================
1. If RMS is not being used as the source of the time calendar, move on to step 2,
otherwise after running time extraction in RMS (see RMS Operations Guide for
details), FTP time_454.txt, start_of_half_month.txt, and wkday.txt from RMS install
directory to the RDW directory <base_directory>/rdw12.0/install.
2. Login to the RDW database server as the UNIX user rdw12dev. Verify the RETL
executable is in the path of your Unix session by typing which rfx at the UNIX
prompt.
3. Change directories to <base_directory>/rdw12.0/install.
4. Verify the C compiler is in the path of your Unix session and the C compiler is in
your Unix library path. At the Unix prompt, enter:
which cc
5. Compile the module cr_time_454, cr_time_13 and cr_time_g with a standard ANSI
C compiler. At the Unix prompt, enter:
cc –g –I. –o cr_time_454 c_utils.c cr_time_454.c
cc –g –I. –o cr_time_13 c_utils.c cr_time_13.c
cc –g –I. –o cr_time_g c_utils.c cr_time_g.c
6. Execute the cr_time.ksh module. At the Unix prompt enter:
cr_time.ksh
7. This script will prompt for the calendar type. Choose 1 for 454 time, 2 for 13 period
time and 3 for 454 with Gregorian time.
8. At the prompt enter the 4-digit year for the beginning and ending of the time
calendar:
Please enter first year to be loaded:
Please enter last year to be loaded:
Note: To determine the beginning and ending fiscal year,
refer to the text file modified above. Verify all months or
periods are included in the text file for the first year; no
partial years are allowed.
One text file will be generated in the install directory for each dimension table.
9. At the UNIX prompt, for 454 time calendar or 13 period time calendar enter:
time_load.ksh
time_trnsfrm_load.ksh
10. At the UNIX prompt, for 454 time with Gregorian time calendar enter
time_load.ksh
g_time_load.ksh
time_trnsfrm_load.ksh
g_time_trnsfrm_load.ksh
====================================
根据 第1点中 see RMS Operations Guide for details,参考 rms-1203-og3.pdf 章节:Running the Time 454 Extract Module 来进行安装:
====================================
1. Log in to the RMS database server as RMS RETL-specific database user. Run the
profile and verify that the MMUSER and PASSWORD variables are set to the RETLsepcific
database user, and the appropriate password. Verify the RETL executable is
in the path of your UNIX session by typing:
%which rfx
2. Change directories to $MMHOME/install.
3. Modify the variable l_path in the extract_time.sql script to reference the UTL_FILE
directory specified in the RMS database parameter file.
4. At the UNIX prompt enter:
%extract_time.ksh
This script generates three files called time_454*.txt, wkday*.txt, and
start_of_half_month*.txt located in the utl_file_dir directory specified in your RMS
database parameter file.
5. Change directories on the UNIX server to $MMHOME/log. Review the log file that
was created or modified.
6. Change directories on the UNIX server to $MMHOME/error. Review the error files
that were created.
7. Move the three output files to $MMHOME/install directory.
====================================
参照RMS提供的以上7个步骤进行安装:
1)执行启动RMS环境变量:source /home/oracle/rmsbatchenv.env
2)重新指定:export MMHOME=/d01/app/retail/rms/db/retlforRDW
3)创建目录:$MMHOME/install
4)cp $MMHOME/rfx/src/extract_time.ksh $MMHOME/install/extract_time.ksh
cp $MMHOME/rfx/src/extract_time.sql $MMHOME/install/extract_time.sql
vi extract_time.sql //修改l_path=$MMHOME/install/
5)执行:cd $MMHOME/install
./extract_time.ksh
在目录$MMHOME/log 和 $MMHOME/error 下产生执行以上脚本的错误日志(extract_time.19960101.txt):
====================================
—————————–
extract_time 11:51:49: Program extract_time started
—————————–
SQL*Plus: Release 10.2.0.3.0 – Production on Tue Nov 11 11:51:49 2008
Copyright (c) 1982, 2006, Oracle. All Rights Reserved.
Connected to:
Oracle Database 10g Enterprise Edition Release 10.2.0.3.0 – 64bit Production
With the Partitioning, OLAP and Data Mining options
SQL> SQL> old 2: l_filename VARCHAR2(50) := ‘&1’;
new 2: l_filename VARCHAR2(50) := ‘time_454.txt’;
old 3: l_filename2 VARCHAR2(50) := ‘&2’;
new 3: l_filename2 VARCHAR2(50) := ‘wkday.txt’;
old 4: l_filename3 VARCHAR2(50) := ‘&3’;
new 4: l_filename3 VARCHAR2(50) := ‘start_of_half_month.txt’;
old 26: FROM &4.calendar c,
new 26: FROM RMS12DEV.calendar c,
old 27: &4.system_options s
new 27: RMS12DEV.system_options s
old 40: FROM &4.calendar c,
new 40: FROM RMS12DEV.calendar c,
old 41: &4.system_options s
new 41: RMS12DEV.system_options s
old 50: FROM &4.calendar;
new 50: FROM RMS12DEV.calendar;
old 54: FROM &4.calendar;
new 54: FROM RMS12DEV.calendar;
old 58: FROM &4.system_options;
new 58: FROM RMS12DEV.system_options;
Unable to open file <$MMHOME/install/time_454.txt>: -29280:ORA-29280: invalid directory path
DECLARE
*
ERROR at line 1:
ORA-29280: invalid directory path
ORA-06512: at line 66
Disconnected from Oracle Database 10g Enterprise Edition Release 10.2.0.3.0 – 64bit Production
With the Partitioning, OLAP and Data Mining options
—————————–
extract_time 11:51:49: ERROR: Program failed – check /d01/app/retail/rms/db/retlforRDW/error/extract_time.19960101
—————————–
====================================
问题一:因根据以上RMS安装指导第4点说明,运行extract_time.ksh会产生time_454*.txt, wkday*.txt, and start_of_half_month*.txt,但目前没有生成此三个文件,并报在相应目录下找不到time_454.txt文件的错误。
解决方案:
登录PL/SQL tool,在Command Windows下查看utl_file_dir的值
SQL> show parameter utl_file_dir
NAME TYPE VALUE
———————————— ———– ——————————
utl_file_dir string /d01/app/oracle/product/10.2.0/db_1/admin/retl/utl_file_tmp, /tmp, /ftphome/gml/working
再修改:l_path=/d01/app/oracle/product/10.2.0/db_1/admin/retl/utl_file_tmp’; /* value of utl_file_dir */
删除之前运行 extract_time.ksh 在目录 $MMHOME/error 中产生的 extract_time.*.txt 文件(有两个文件),再次运行:
./extract_time.ksh
执行正确,日志文件显示如下:
====================================
—————————–
extract_time 13:29:34: Program extract_time started
—————————–
SQL*Plus: Release 10.2.0.3.0 – Production on Wed Nov 12 13:29:34 2008
Copyright (c) 1982, 2006, Oracle. All Rights Reserved.
Connected to:
Oracle Database 10g Enterprise Edition Release 10.2.0.3.0 – 64bit Production
With the Partitioning, OLAP and Data Mining options
SQL> SQL> old 2: l_filename VARCHAR2(50) := ‘&1’;
new 2: l_filename VARCHAR2(50) := ‘time_454.txt’;
old 3: l_filename2 VARCHAR2(50) := ‘&2’;
new 3: l_filename2 VARCHAR2(50) := ‘wkday.txt’;
old 4: l_filename3 VARCHAR2(50) := ‘&3’;
new 4: l_filename3 VARCHAR2(50) := ‘start_of_half_month.txt’;
old 26: FROM &4.calendar c,
new 26: FROM RMS12DEV.calendar c,
old 27: &4.system_options s
new 27: RMS12DEV.system_options s
old 40: FROM &4.calendar c,
new 40: FROM RMS12DEV.calendar c,
old 41: &4.system_options s
new 41: RMS12DEV.system_options s
old 50: FROM &4.calendar;
new 50: FROM RMS12DEV.calendar;
old 54: FROM &4.calendar;
new 54: FROM RMS12DEV.calendar;
old 58: FROM &4.system_options;
new 58: FROM RMS12DEV.system_options;
SQL> Disconnected from Oracle Database 10g Enterprise Edition Release 10.2.0.3.0 – 64bit Production
With the Partitioning, OLAP and Data Mining options
—————————–
extract_time 13:29:34: Program completed succesfully
—————————–
====================================
同时产生相应文件:
(i)在目录$MMHOME/log 和 $MMHOME/error 下产生执行脚本日志文件(extract_time.19960101.txt);
(ii)在目录$ORACLE_HOME/admin/retl/utl_file_tmp 下产生 time_454.txt、wkday.txt、start_of_half_month.txt 三个数据文件;
登录RMS数据库,查看日期数据:select * FROM RMS12DEV.calendar;
接着往下操作:
cp $ORACLE_HOME/admin/retl/utl_file_tmp/time_454.txt $MMHOME/install/time_454.txt
cp $ORACLE_HOME/admin/retl/utl_file_tmp/wkday.txt $MMHOME/install/wkday.txt
cp $ORACLE_HOME/admin/retl/utl_file_tmp/start_of_half_month.txt $MMHOME/install/start_of_half_month.txt
二、接着参考 RDW Database 安装指导文档 rdw-120-ig-db.pdf 章节:Create Time in RDW 进行操作:
1) source /home/oracle/rdw_profile_ora
2) cp /d01/app/retail/rms/db/retlforRDW/install/time_454.txt $MMHOME/install/time_454.txt
cp /d01/app/retail/rms/db/retlforRDW/install/wkday.txt $MMHOME/install/wkday.txt
cp /d01/app/retail/rms/db/retlforRDW/install/start_of_half_month.txt $MMHOME/install/start_of_half_month.txt
3) which cc
返回结果:/usr/bin/cc
/usr/bin/cc -g -I. -o cr_time_454 c_utils.c cr_time_454.c
/usr/bin/cc -g -I. -o cr_time_13 c_utils.c cr_time_13.c
/usr/bin/cc -g -I. -o cr_time_g c_utils.c cr_time_g.c
4) 执行:
cd $MMHOME/install
./cr_time.ksh
显示及输入如下信息:
Do you wish to use 454 time calendar, 13 period time calendar or 454 time calendar with Gregorian time calendar?
Enter 1 when you wish to use 454 time calendar,
Enter 2 when you wish to use 13 period time calendar,
Enter 3 when you wish to use 454 with Gregorian time calendar. [1, 2 or 3]
1
Please enter first year to be loaded:
1994-01-03
Please enter last year to be loaded:
2023-12-04
Starting the threads
All threads complete
Flow ran successfully
Started
Terminated Ok
备注:
(i)上面提示中输入的启始年月日,是根据$MMHOME/install 目录下面的time_454.txt 文档中存在的最小最大日期输入的;如果输入的日期不在 time_454.txt 文件中列出来的日期范围内,则会产生错误;
(ii)如果RDW日期表中的初始日期是根据 time_454.txt 文档中的日期导入,那如果需要更大的日期时,是否要手动编辑往time_454.txt 文件中增加日期;如果这样做,那工作量可能很大,并根据自带 time_454.txt 文件看,产生日期的有方式不是通常年月的初末形式,而是从每个月第一个星期一开始。所以以后Retail各模板的日期或区间的初始化是业务顾问在系统中建立,还是从后台编辑此文本再进行导入?
(iii)上面提示中选择输入 Calendar type 时,我选择的是 1 for 454 time;而真正在系统中需要什么样的 Calendar type 还得请业务顾问确认一下。
(iv)执行了cr_time.ksh脚本后,在$MMHOME/install中产生许多time_*_dm.txt 数据文件,记录各种类型的数据,以供导入到RDW基表。
5)因为执行了1 for 454 time,所以执行第9步,即运行:time_load.ksh 和 time_trnsfrm_load.ksh 脚本:
./time_load.ksh
在目录下$MMHOME/log 和 $MMHOME/error 下产生执行以上脚本的错误日志(time_load.20010310.txt):
====================================
—————————–
time_load 13:58:09: Loading initial data files into TIME_DAY_DM TIME_YR_DM TIME_HALF_DM TIME_MTH_DM TIME_WK_DM TIME_QTR_DM in time_load
—————————–
Starting the threads
WARN – W149: [changecapture:1] “value” is not specified. Comparing all fields.
Consider specifying the “value” property for better performance.
FATAL – retl 12.0.1 build 1142 (1.4.2_04-b05 :: Sun Microsystems Inc. :: i386 :: Linux :: 2.6.9-42.0.0.0.1.ELsmp)
FATAL – E135: Exception in operator [sort:2]
E108: java.io.IOException: gsort: not found
—————————–
time_load 13:58:11: ERROR: Loading time flat file rdw12dm.TIME_DAY_DM failed
—————————–
====================================
问题二:正常情况是把上一步产生的 time_*_dm.txt 数据文件中的数据写入到对应的RDW日期基表中,但出现以上错误,不知何因,还在查找原因中?
解决方案:
6)./time_trnsfrm_load.ksh
在目录下$MMHOME/log 和 $MMHOME/error 下产生执行以上脚本的错误日志(time_trnsfrm_load.20010310.txt):
====================================
./time_trnsfrm_load.ksh[30]: LAST_YR_DAY_IDNT
LAST_HALF_DAY_IDNT
LAST_QTR_DAY_IDNT
LAST_MTH_DAY_IDNT
LAST_WK_DAY_IDNT: bad number
====================================
问题三:正常情况也是写入RDW日期表的值,但出现以上错误,不知何因,还在查找原因中?
解决方案:
2.3.16 Populate Static Dimension Data
1 ./timelfldm.ksh
在目录下$MMHOME/log 和 $MMHOME/error 下产生执行以上脚本的日志(timelfldm.20010310.txt):
====================================
—————————–
timelfldm 15:15:12: Loading time LIKE FOR LIKE tables
—————————–
SQL*Plus: Release 10.2.0.3.0 – Production on Tue Nov 11 15:15:12 2008
Copyright (c) 1982, 2006, Oracle. All Rights Reserved.
Connected to:
Oracle Database 10g Enterprise Edition Release 10.2.0.3.0 – 64bit Production
With the Partitioning, OLAP and Data Mining options
SQL> SQL>
0 rows deleted.
SQL>
Commit complete.
SQL> Disconnected from Oracle Database 10g Enterprise Edition Release 10.2.0.3.0 – 64bit Production
With the Partitioning, OLAP and Data Mining options
Starting the threads
All threads complete
Flow ran successfully
SQL*Plus: Release 10.2.0.3.0 – Production on Tue Nov 11 15:15:14 2008
Copyright (c) 1982, 2006, Oracle. All Rights Reserved.
Connected to:
Oracle Database 10g Enterprise Edition Release 10.2.0.3.0 – 64bit Production
With the Partitioning, OLAP and Data Mining options
SQL> SQL>
0 rows deleted.
SQL>
Commit complete.
SQL> Disconnected from Oracle Database 10g Enterprise Edition Release 10.2.0.3.0 – 64bit Production
With the Partitioning, OLAP and Data Mining options
Starting the threads
All threads complete
Flow ran successfully
—————————–
timelfldm 15:15:15: Loading time LIKE FOR LIKE tables completed successfully
—————————–
====================================
2 ./vchragedm.ksh
在目录下$MMHOME/log 和 $MMHOME/error 下产生执行以上脚本的日志(vchragedm.20010310.txt):
====================================
—————————–
vchragedm 15:17:18: Loading voucher age band table
—————————–
SQL*Plus: Release 10.2.0.3.0 – Production on Tue Nov 11 15:17:18 2008
Copyright (c) 1982, 2006, Oracle. All Rights Reserved.
Connected to:
Oracle Database 10g Enterprise Edition Release 10.2.0.3.0 – 64bit Production
With the Partitioning, OLAP and Data Mining options
SQL> SQL>
0 rows deleted.
SQL>
Commit complete.
SQL> Disconnected from Oracle Database 10g Enterprise Edition Release 10.2.0.3.0 – 64bit Production
With the Partitioning, OLAP and Data Mining options
Starting the threads
All threads complete
Flow ran successfully
—————————–
vchragedm 15:17:20: Loading voucher age band table completed successfully
—————————–
====================================
此章节的两个脚本导入都成功,可用rdw12dm登录RDW数据库进行验证基表产生相应数据:
SELECT * FROM time_last_yr_by_day_lfl_dm;
SELECT * FROM time_last_yr_by_wk_lfl_dm;
SELECT * FROM vchr_age_band_dm;