
问题十、新建租户失败
现象:在2026/01/09下载的版本上,有同事 发现以平台租户下系统管理员身份创建新的租户HAND-DEV 出错
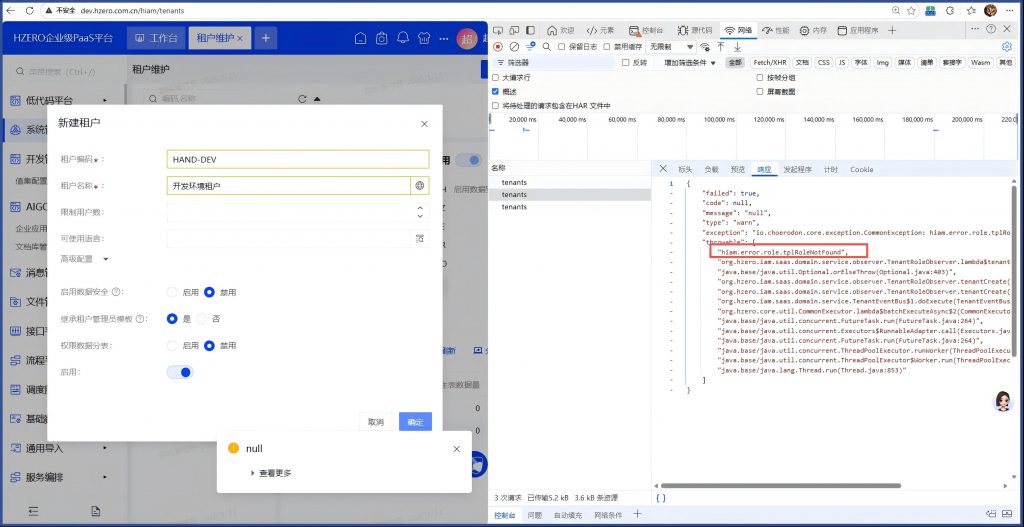
分析:检查/网络 :调用的是iam服务的API , 返回200 Ok,响应中提示的错误是:
“exception”:”io.choerodon.core.exception.CommonException: hiam.error.role.tplRoleNotFound”,
“throwable”: [
“hiam.error.role.tplRoleNotFound”, “org.hzero.iam.saas.domain.service.observer.TenantRoleObserver.lambda$tenantCreate$1(TenantRoleObserver.java:59)”,
检查hzero-iam 服务的后台日志,发现在这个错误之前有另一个错误:
Exception in thread “pool-40-thread-9” org.springframework.dao.QueryTimeoutException: Redis command timed out
检查redis容器的CPU占用和内存占用都很低,看起来Redis服务没啥问题。
继续检查redis:
#查询耗时超过50毫秒的客户端命令:
/data # redis-cli 127.0.0.1:6379> config set slowlog-log-slower-than 50000
让豆包对输出内容进行分析:
1. 高风险耗时命令(直接导致超时)
SET “hpfm:language:auto-refresh:lock”:耗时 165.5ms(第 4 条)
DEL “apaas:data-transport:active:hzero-lowcodedata”:耗时 132.1ms(第 5 条)
SET “apaas:data-transport:active:hzero-modeler”:耗时 44.9ms(第 7 条)
如果你的 Spring 配置中 redis.timeout 是默认的 2000ms(2 秒),单条命令 165ms 本不该超时,但高并发下多条慢命令排队,总耗时就会超过阈值(比如 10 条 160ms 的命令排队,总耗时 1.6 秒,接近 2 秒超时)。
2. 潜在风险命令(HGETALL)
HGETALL “hiam:doc:permission:rule:hadm_notice_publisher”(第 13 条)
HGETALL “hpfm:permission:hadm_service_route”(第 14 条)
HGETALL 是全量获取哈希表的命令,如果哈希表中字段数多(比如上千个),即使单次耗时 11.5ms(11546 微秒),高频率执行也会:
占满 Redis 单线程(Redis 单线程每秒处理能力有限);
导致后续命令排队,总耗时累积超时。
#继续查询各命令执行次数:
$ docker exec -it redis-hzero redis-cli info commandstats | sort -k 4 -r
输出结果中,有一条比较特殊:
cmdstat_hgetall:calls=15346,usec=-1069515,usec_per_call=-69.69,rejected_calls=0,failed_calls=0
豆包分析:
calls=15008:该命令执行了 1.5 万次,频次极高;
usec=-1073589:耗时字段为负数,说明 Redis 内部的耗时计数器已溢出,实际总耗时远超千万微秒(即数秒甚至数十秒);
即使单次平均耗时显示 -71.53(溢出导致),结合慢查询日志中 HGETALL 实际耗时 11-17ms,1.5 万次执行的总耗时会完全占满 Redis 单线程,导致后续所有命令排队。
豆包总结:
核心根因:HGETALL 执行 1.5 万次且耗时溢出,占满 Redis 单线程,导致其他命令排队超时;
紧急方案:调大 Redis 客户端超时时间和连接池,缓解超时问题;
根本方案:用 HSCAN 替换 HGETALL,分批获取 Hash 数据,清理 / 拆分大 Key;
长期保障:添加 AOP 监控,提前发现慢命令,避免问题复发。
我估计在所有服务一起启动的时候,可能出现redis超时,不过等服务全部启动完成后就不会有超时问题了。所以这个不太可能导致hiam.error.role.tplRoleNotFound这个问题,也就是不太可能因为日志中的redis超时,导致租户创建失败。
#开放平台全平台搜索“tplRoleNotFound” 未搜到任何结果。
#到非Docker环境去创建租户:出现问题是一样的。
#我上次创建“低代码演示租户”的时候,没有出现过这个问题,我看下升级日志
2025-09-11 升级飞搭 从 2.9.1-1.12.BETA.8 到 2.10.0.RELEASE
我上次创建“低代码演示租户”的时候是在这次升级之前。
看了这之后的历次升级动作,只有在2025-09-26升级底座的时候升级过iam服务。
2025-09-26 升级HZERO底座 从1.12.1.RELEASE 到 1.12.2.RELEASE
当时,iam服务从1.12.1.RELEASE替换成1.12.2.RELEASE
那我把iam服务的版本退回到1.12.1.RELEASE行不行?尝试一下:
更改:
/d02/hzero/project/pom.xml
/d02/hzero/project/ps-iam-saas/pom.xml
尝试了,不行,iam服务退回到1.12.1.RELEASE后,系统就无法登录了。
还是恢复到1.12.2.RELEASE
继续思考:报错信息是tplRoleNotFound,是不是模板角色未找到?
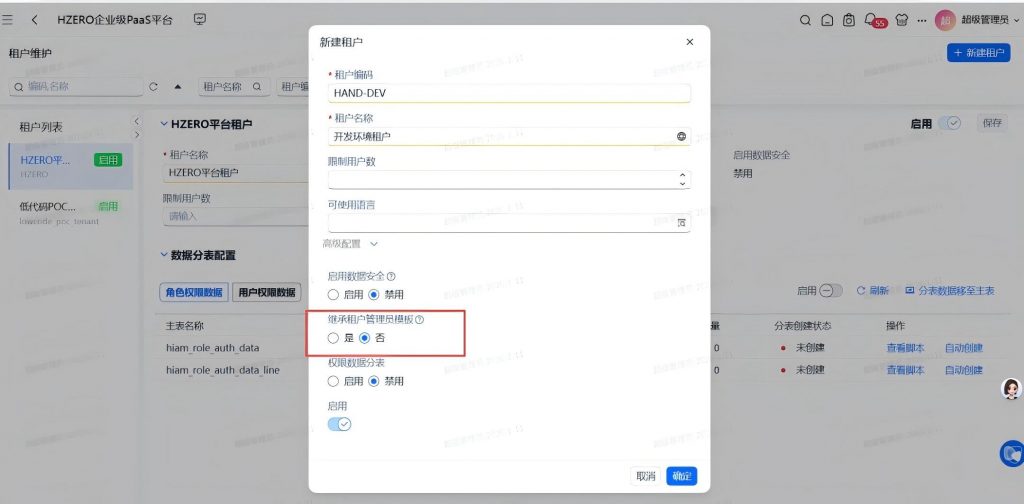
尝试下 在创建租户时“集成租户管理员模板”选择“否”,结果错误跟原来是一样的。
看下有无更新的补丁版:最新版是2025/03/18 的版本,后面没有更新的了。
那可能是数据问题?
搞不定了,明天上班,去问下产研吧!
第二天问了产研,产研说看下数据,下面的SQL能否查到,如果查不到原因是什么,针对原因解决即可:
use hzero_platform;
select
ir.id,
ir.name as “name”,
ir.code as “code”,
ir.fd_level,
ir.h_tenant_id,
ir.h_inherit_role_id,
ir.h_parent_role_id,
ir.tpl_role_name,
il.id label_id,
il.name label_name,
il.type label_type
from iam_role ir
join hiam_label_rel hlr on (
hlr.data_type = ‘ROLE’
and hlr.data_id = ir.id
)
join iam_label il on il.id = hlr.label_id
where ir.is_enabled = 1
and il.preset_flag = 1
and il.enabled_flag = 1
and exists (
select 1
from iam_label il
join hiam_label_rel hlr on (
hlr.data_type = ‘ROLE’
and hlr.label_id = il.id
)
where
hlr.data_id = ir.id
and il.enabled_flag = 1
and il.preset_flag = 1
and il.name = ‘TENANT_ROLE_TPL’
)
直接结果是查不到数据,分析原因是因为 hzero_platform.iam_role表中租户管理员模板的is_eanbled标记错了,应该是1,不是0,才能被上面SQL查出来。
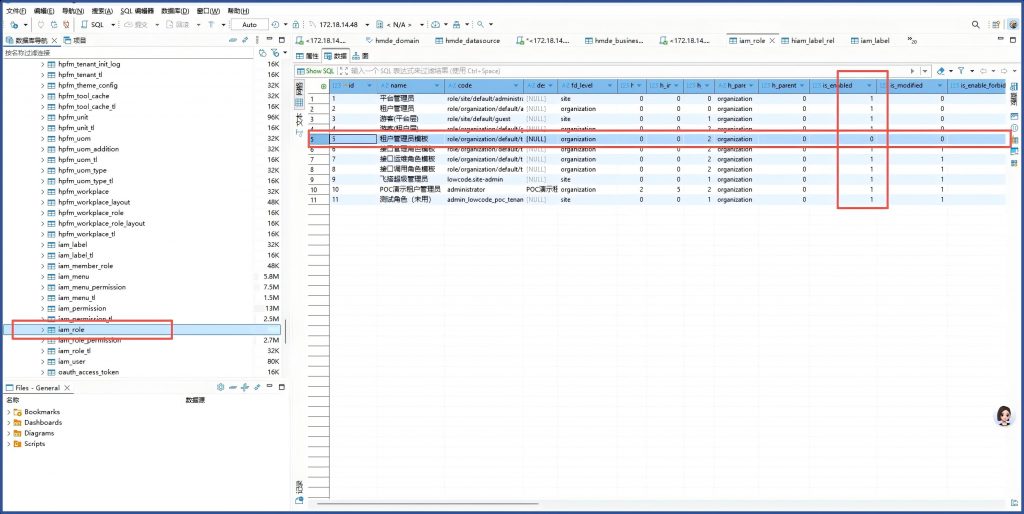
解决方案:把这个标记更新成1
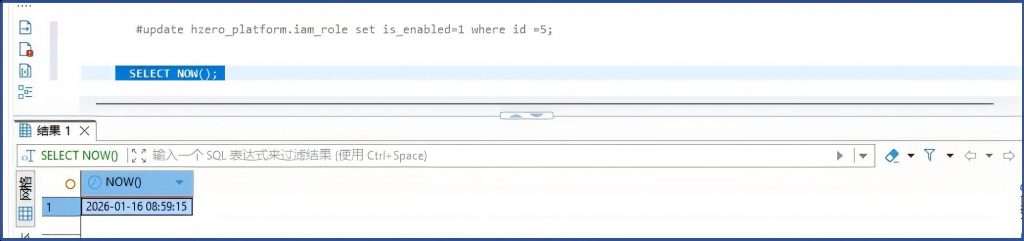
update hzero_platform.iam_role set is_enabled=1 where id =5;
更新完成后再次尝试新建租户:
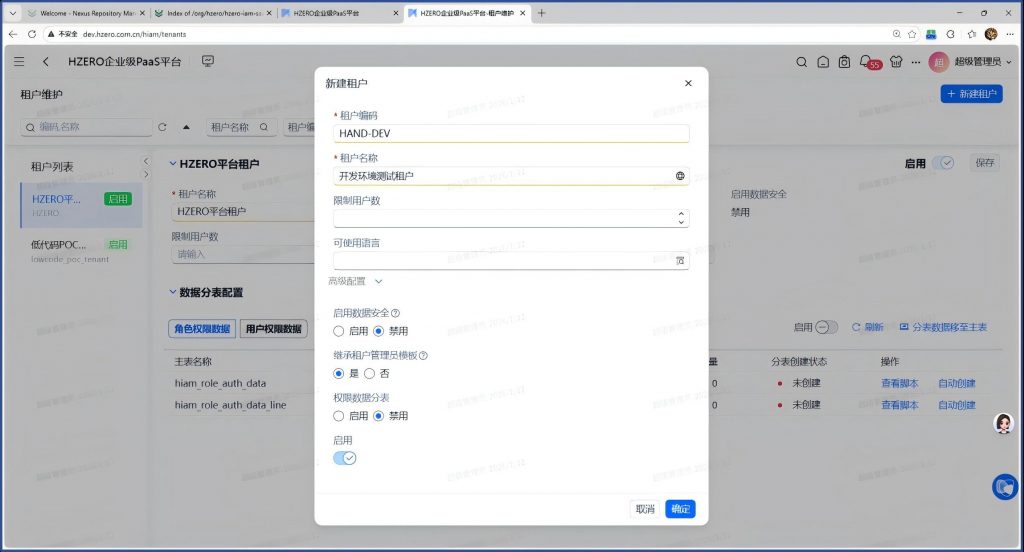
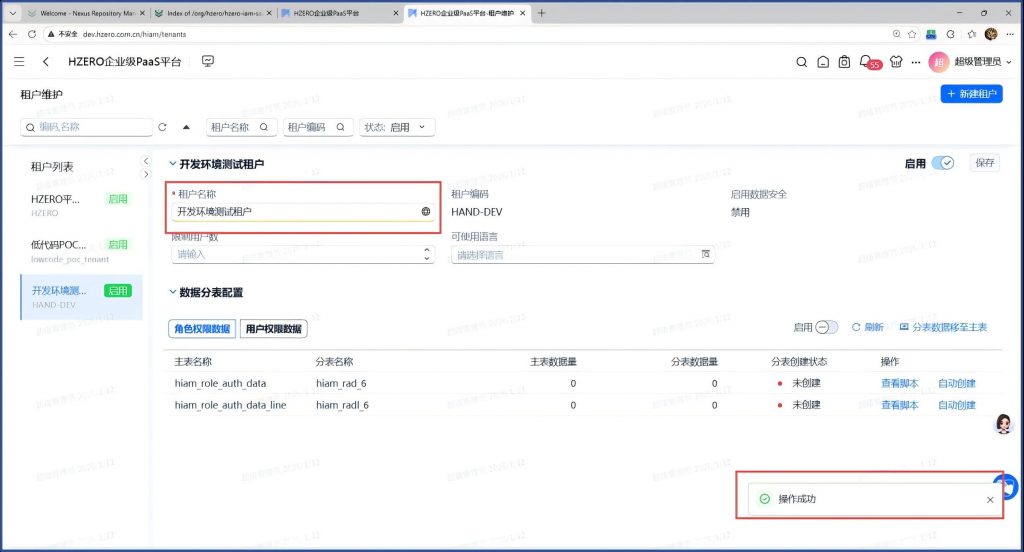
创建成功。问题解决。
问题十一、集成平台,导入编排报错
产研说这个问题升级到1.8的最新版本可以解决掉,集成平台产研组,提供了一个工具,获取某个中版本的最新稳定版小版本。
我们原来的编排服务版本是1.8.1.RELEASE的,查了下最新稳定版是1.8.2.RELEASE
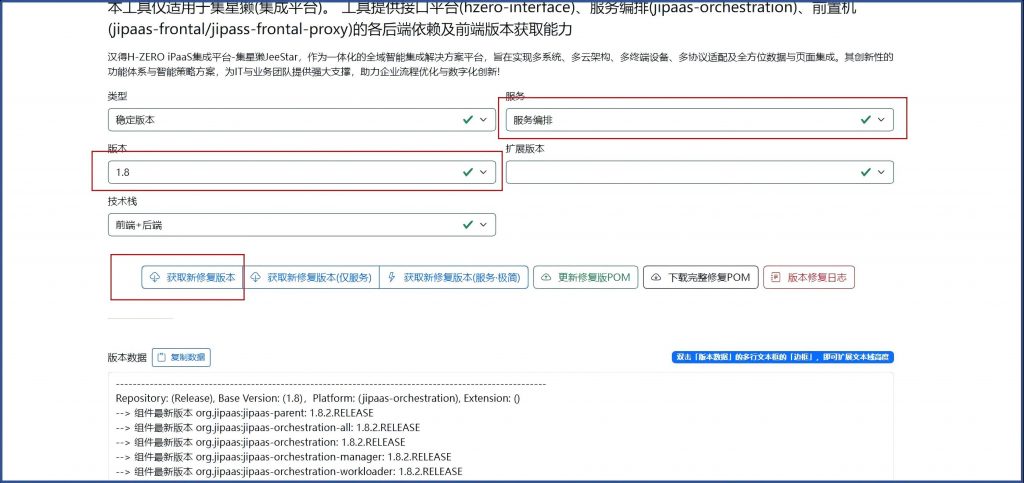
把集成平台的父parent和编排的POM都改成1.8.2.RELEASE之后重新构建成功但启动服务失败。
思考:是否agent的版本依赖有更新,原来用的agent是license-agent110(别名:license-agent103), 改成 license-agent112a试试看。
果然,改了之后服务启动成功。
测试,编排服务正常,但出现调用接口平台错误:
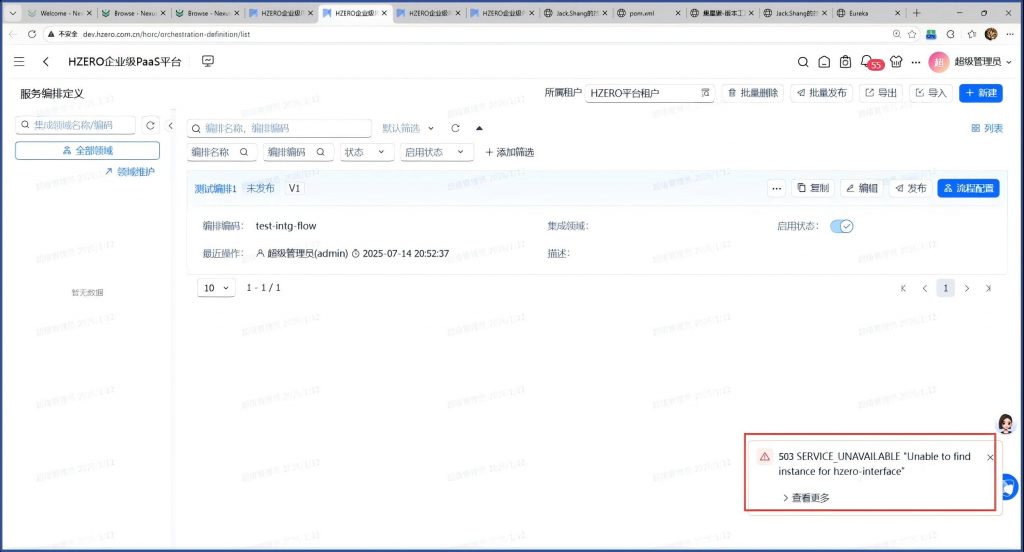
查接口平台日志,发现错误:
Caused by: org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name ‘externalInvokeAdvisor’: Unsatisfied dependency expressed through field ‘advice’: Error creating bean with name ‘internalInvokeAdvisor’: Unsatisfied dependency expressed through field ‘advice’: Error creating bean with name ‘internalInvokeAdvice’: Unsatisfied dependency expressed through field ‘objectMapper’: Error creating bean with name ‘interfaceGatewayConfig’ defined in URL [jar:nested:/d02/hzero-ipaas/project/ps-jipaas-interface/target/ps-jipaas-interface.jar/!BOOT-INF/lib/hzero-interface-gateway-1.1.1.RELEASE.jar!/org/hzero/interfaces/gateway/config/InterfaceGatewayConfig.class]: Error creating bean with name ‘org.springframework.cache.annotation.ProxyCachingConfiguration’: No bean named ‘org.springframework.context.annotation.ConfigurationClassPostProcessor.importRegistry’ available
元宝分析原因:
主要原因与解决方案
这种内部 Bean 缺失通常不直接是业务代码错误,而是由以下情况引发的 Spring 容器初始化异常:
可能原因
说明与解决方案
版本冲突
这是最可疑的原因。不同 Spring 组件(如 spring-context, spring-aop, spring-cache)或第三方库(如 MyBatis)的版本不兼容,可能导致内部 Bean 注册紊乱 。解决方案:检查项目的依赖树(如使用 mvn dependency:tree或 gradle dependencies),确保所有 Spring 相关依赖的版本保持一致且兼容。
配置顺序或覆盖问题
自定义配置或 Bean 可能意外干扰了 Spring 容器的标准初始化流程。解决方案:检查是否有自定义配置类(特别是使用了 @EnableCaching或相关 AOP 配置)或通过 @Primary、@Qualifier注解覆盖了默认 Bean,暂时注释掉这些配置来排查 。
项目构建或缓存问题
旧的编译文件或损坏的依赖缓存可能导致运行时类路径不完整。解决方案:执行清理和重新构建操作(如 mvn clean compile或清理 IDE 的缓存并重启)。
但我认为不是这个原因,因为这个服务之前一直启动正常,如果有上述问题,不可能之前启动正常。
于是我重启了接口平台服务:
$ cd /d02/hzero-ipaas/project/ps-jipaas-interface
$ bash run_nobuild.sh
重启后服务正常了,编排服务也正常了。
重新打包编排服务的镜像:
- 拷贝文件
#Windows PowerShell:
cp \\wsl.localhost\Ubuntu-2204-hzero-openjdk\d02\hzero-ipaas\project\ps-orchestration-all\target\ps-orchestration-all.jar \\wsl.localhost\Ubuntu-22.04\d01\hzero-dockers\hzero-orchestration-docker\
cp \\wsl.localhost\Ubuntu-2204-hzero-openjdk\d02\hzero\project\ps-license\licenseAgent\license-agent112a.jar \\wsl.localhost\Ubuntu-22.04\d01\hzero-dockers\hzero-orchestration-docker\
- 更改Dockerfile,把license-agent110改成license-agent112a
COPY license-agent112a.jar /license-agent112a.jar
- 更改docker-compose.yml ,把license-agent110改成license-agent112a
– AGENT=-javaagent:/license-agent112a.jar
4、目标环境构建Docker镜像
$ cd /d01/hzero-dockers/hzero-orchestration-docker
$ docker build -t hzero-orchestration-all-jk-demo:1.12 .
5、测试启动容器,可以正常启动服务;
6、save & 更新
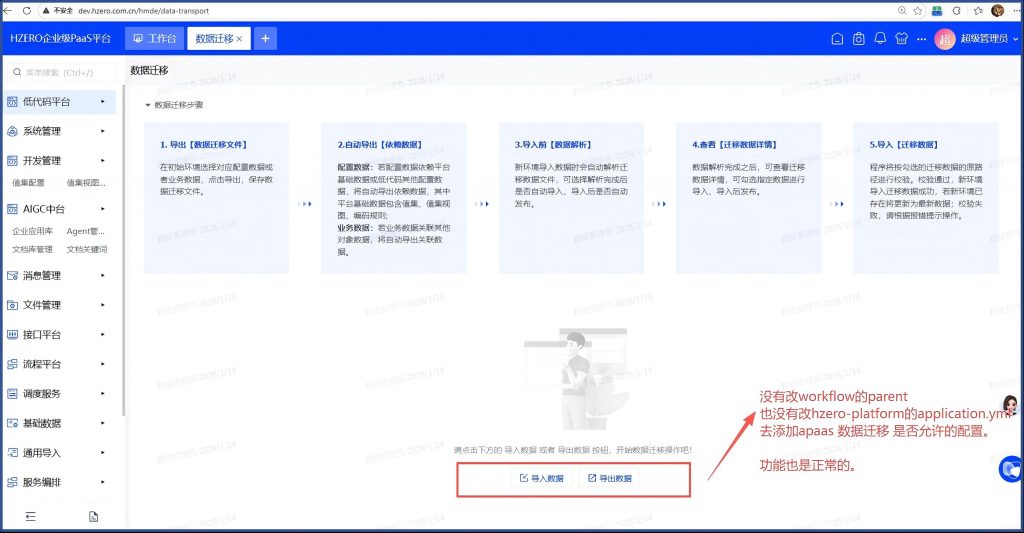
问题十二、低代码平台数据迁移功能异常
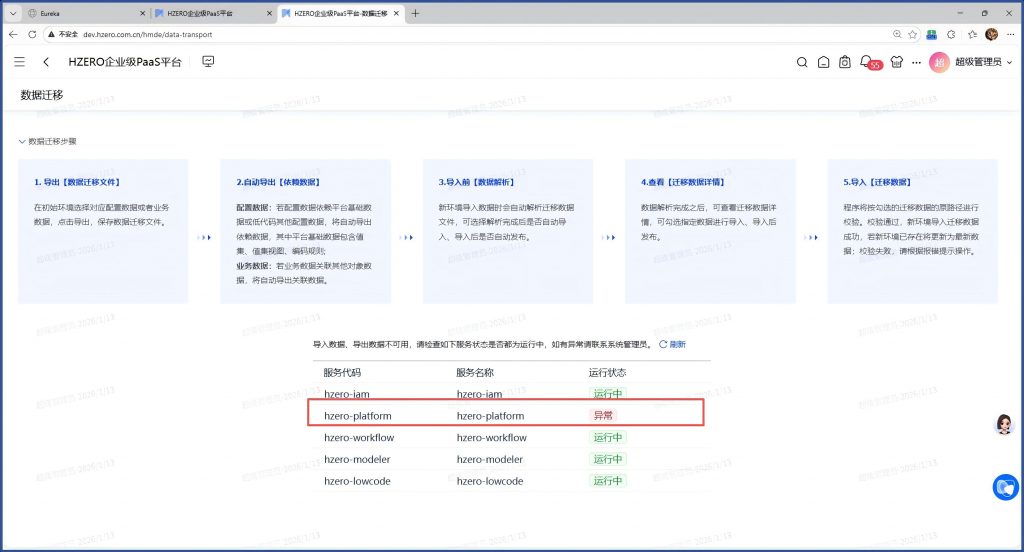
路径:低代码平台/资源管理/数据迁移,显示有两个服务不可用。
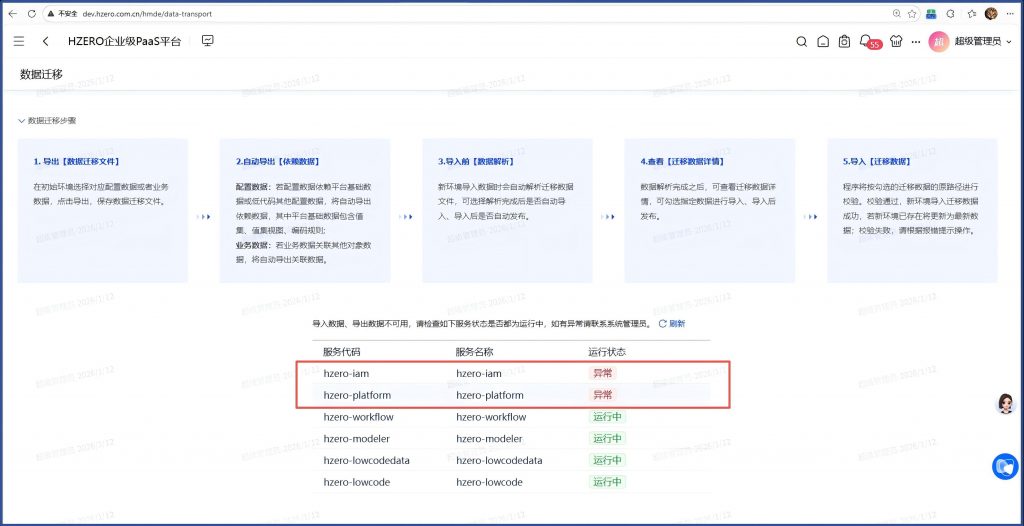
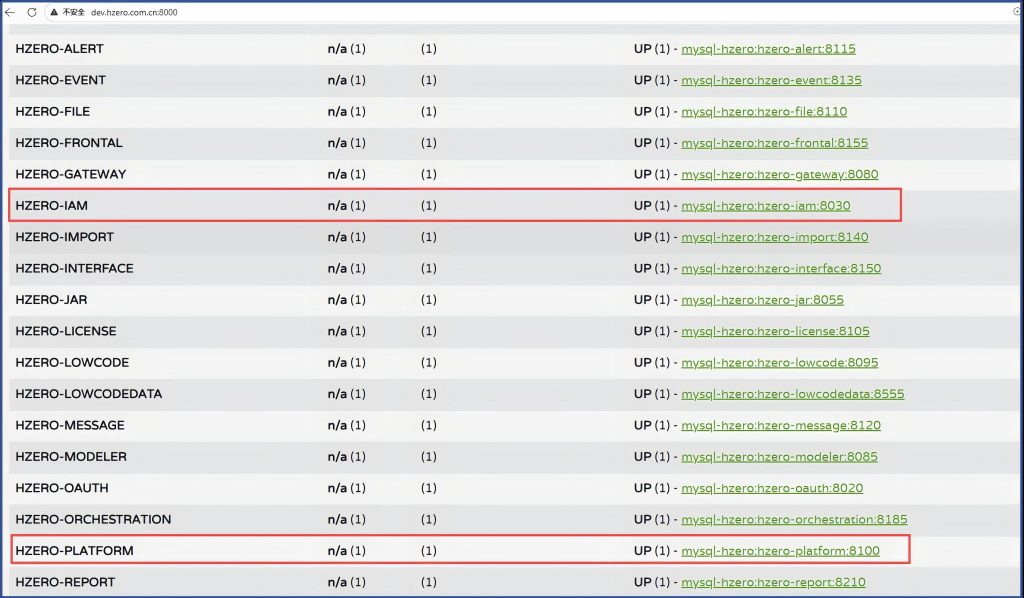
分析:实际情况是这两个服务启动状态正常:
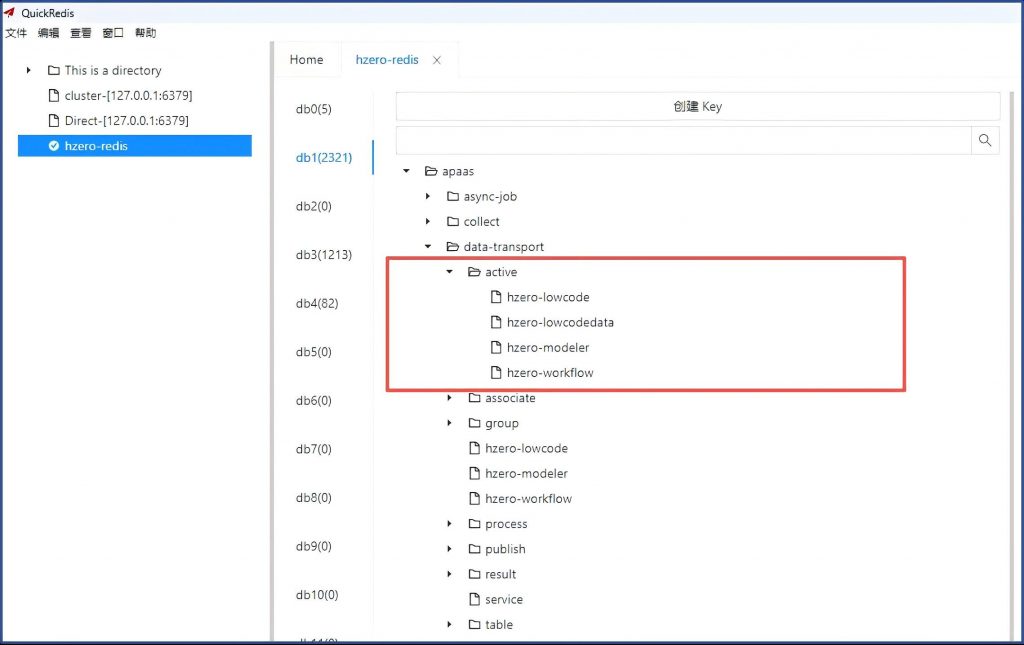
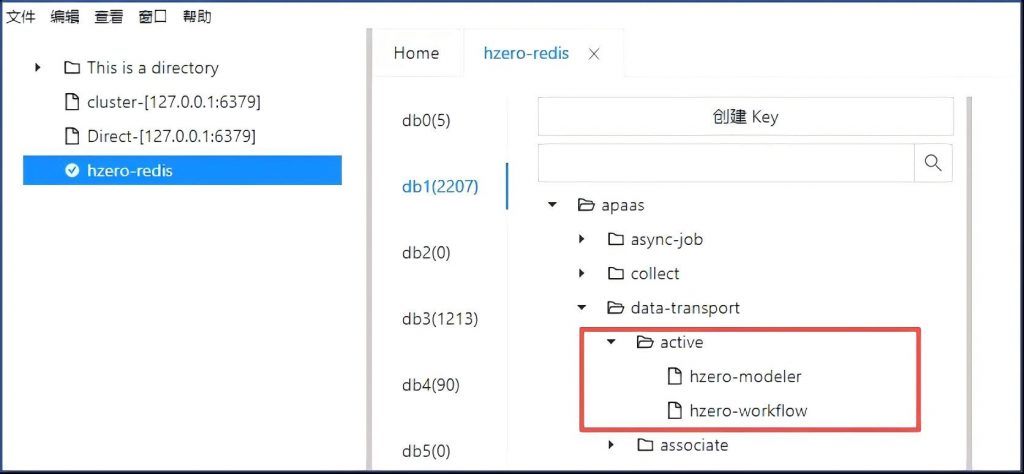
产研的说法是,这个界面的服务状态是从Redis中读取的,查Redis的特定键下面内容,确实缺了这两个服务:
有个疑问是,之前曾经成功导出过数据,这个界面曾经处理到正常状态的,可以参考:
Jack.Shang的技术博客 » HZERO PaaS平台demo升级笔记
那为什么现在又提示这种错误了呢?有个同事的说法是:服务第一次加载的时候会把服务加载到active目录下,那个时候可能会显示正常,然后有服务会去刷新数据,刷新的时候,会看服务的application.yml中有没有配置,如果没有就去掉了:
Hzero:
apaas:
data-transport:
enable: true
我看了自己的hzero-iam服务的配置,配置是有的,但缩进有问题:
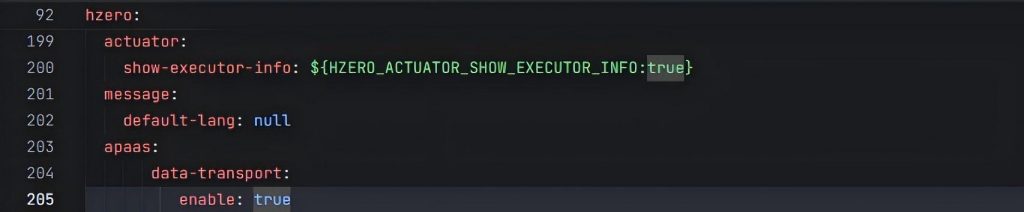
更改缩进后再重启hzero-iam服务,发现Redis中就有了:
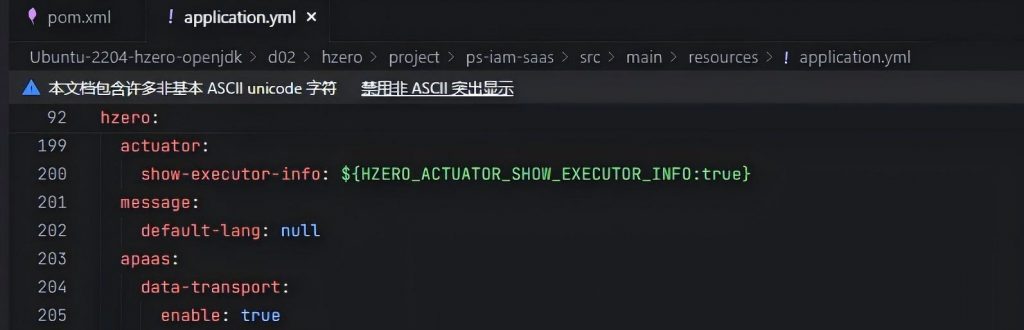
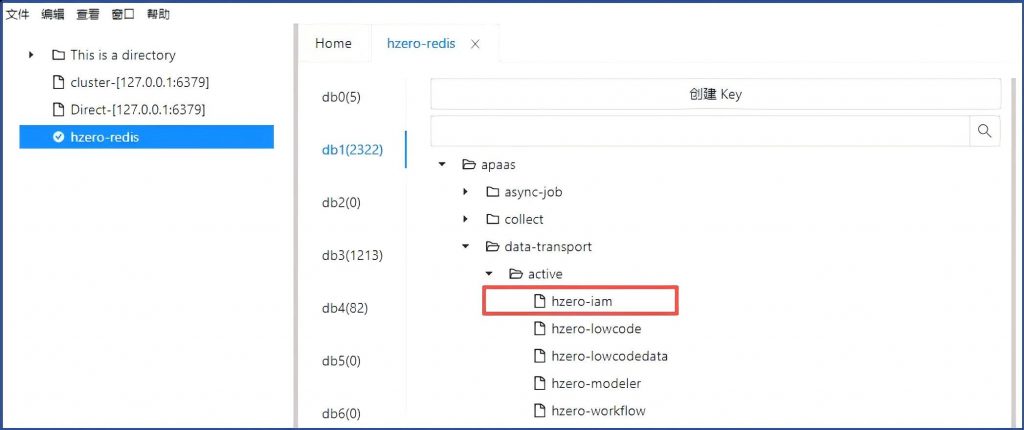
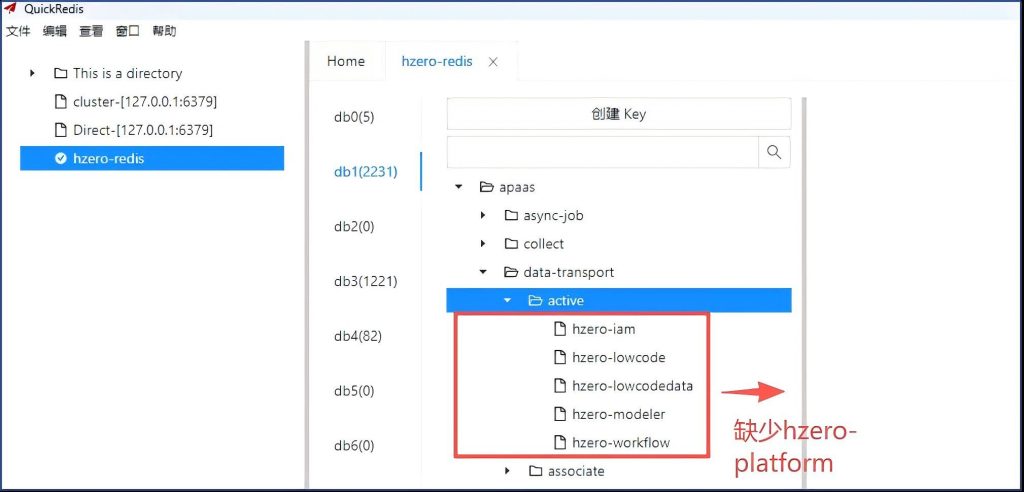
同样在hzero-platform的application.yml中检查发现,缺少
hzero:
apaas:
data-transport:
enable: true
也加上,再重启hzero-platform服务, 这次不稳定,发现active健下的服务反而变少了。
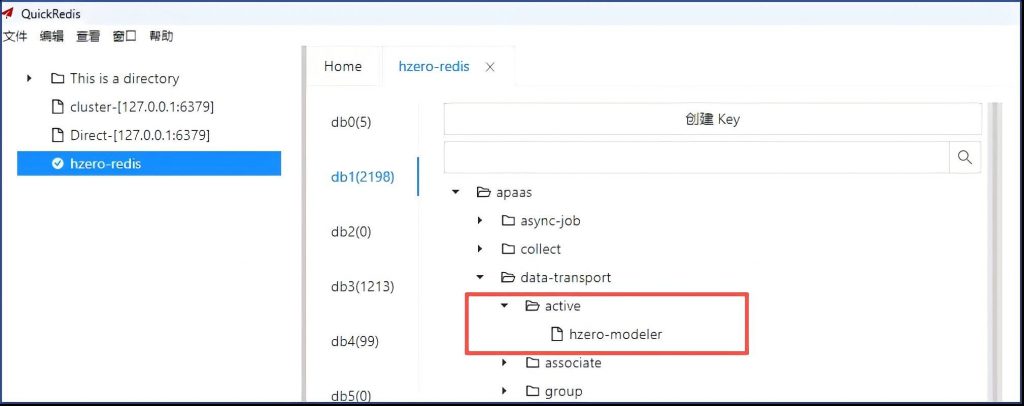
估计这个健值是hzero-modeler服务里面的定期程序刷进去的,重启hzero-modeler服务。
结果还是老样子。
hzero-modeler服务的application.yml中去掉hzero-lowcodedata,仅保留5个服务即可:
hzero:
apaas:
data-transport.include-services: hzero-modeler, hzero-lowcode, hzero-platform, hzero-workflow,hzero-iam
重新构建启动hzero-modeler服务
另有同事反馈说:hzero-workflow 父工程的POM中的parent要换成hzero-apaas-parent
<parent>
<groupId>org.hzero</groupId>
<artifactId>hzero-apaas-parent</artifactId>
<version>2.10.0-1.12.RELEASE</version>
</parent>
另外开放平台文档中说明的hzero-workflow配合低代码平台要添加跟hzero-modelerxiangguan 的四个依赖,但由于在hzero-workflow本身的POM中都已经添加了,所以在我们自己套壳的ps-workflow的POM中就不需要添加了. 你可以在本地maven库中查看hzero-workflow的POM文件内容,就明白了。
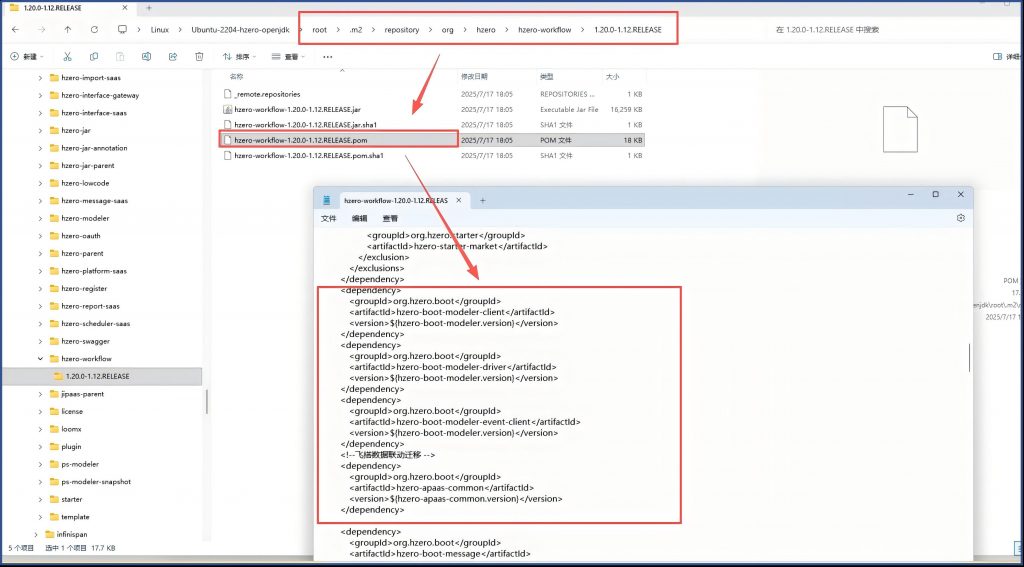
#重新构建启动hzero-workflow服务
重启之后,进去了:
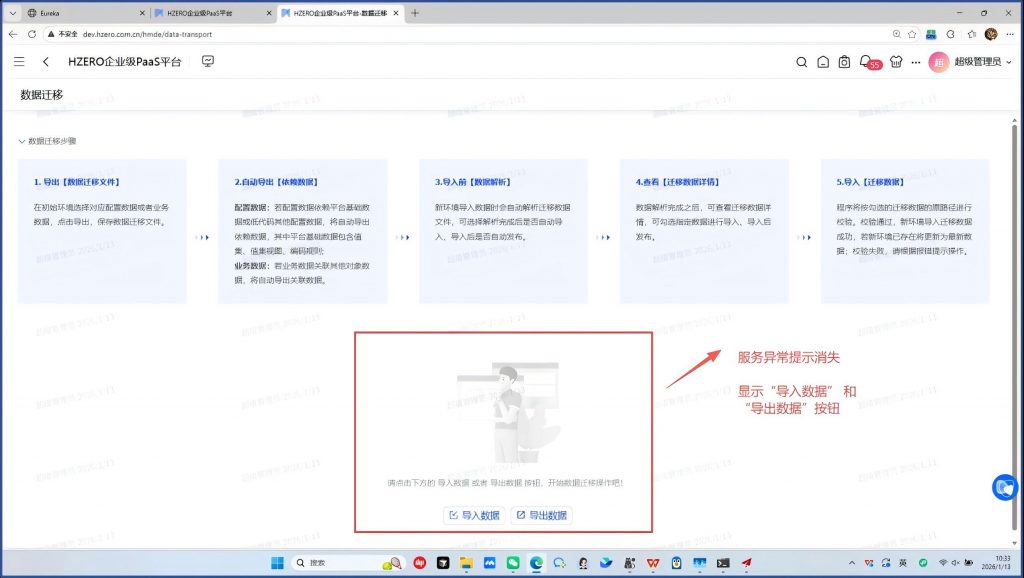
今天先到这里,关闭所有服务,明天再搞:
第二天重启所有服务之后,发现正常了:
那这是算稳定性不够吗? 我再重启hzero-modeler服务试试看:
$ cd /d02/hzero-apaas/project/ps-modeler
$ bash run.sh
重启之后,显示异常:
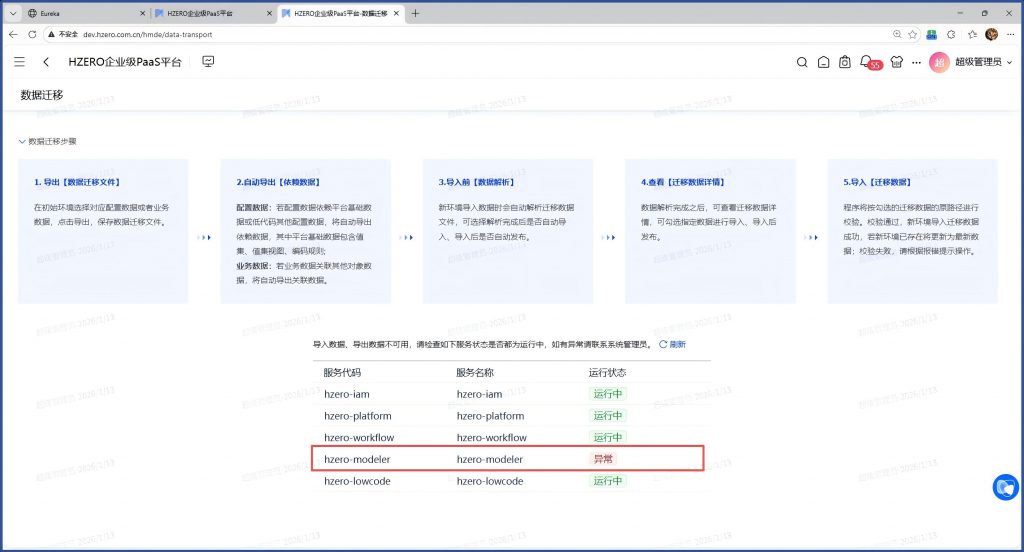
过一分钟后点”刷新”,又正常了:
如果我们, 去掉redis持久化配置,清空redis , 再重启会怎样?
我们发现hzero-platform 异常了,实际就是没有进入redis
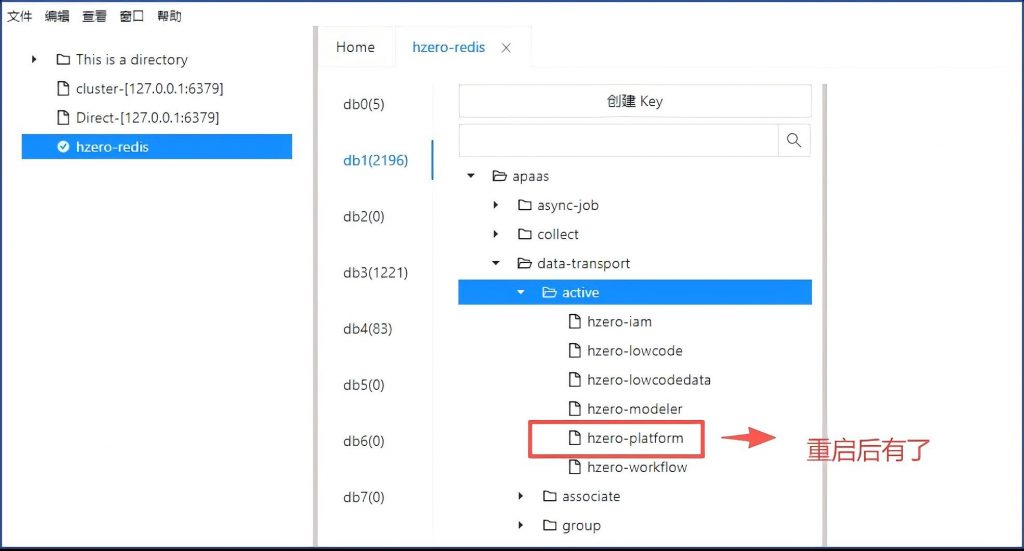
而且过了10多分钟,多次刷新也没用。
#重启下hzero-platform服务试试看:
$ cd /d02/hzero/project/ps-platform
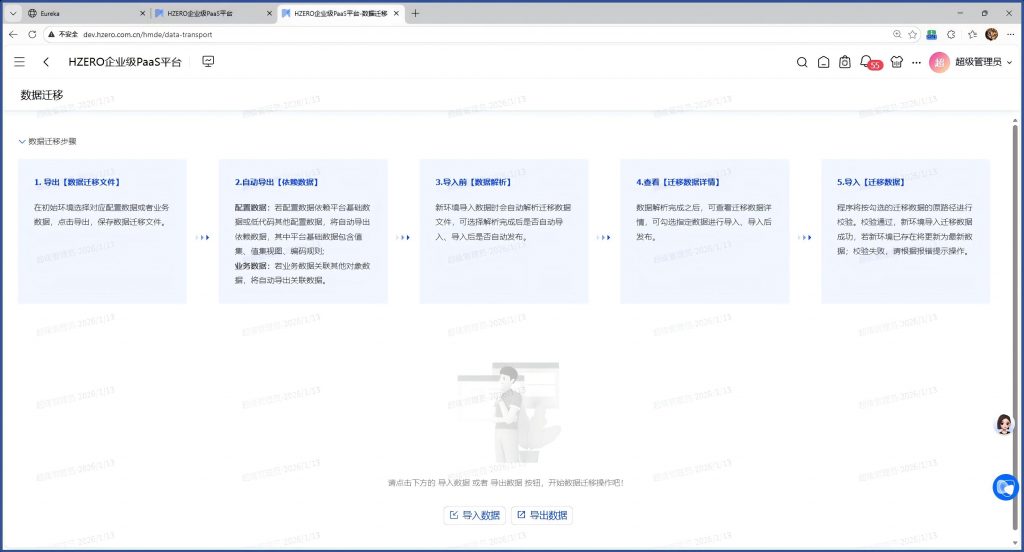
$ bash run_nobuild.sh
数据迁移界面又正常了:
为什么要这么设计呢? 为什么不直接去注册中心检查服务是否Ok呢?为什么要到redis里面去记录下服务状态OK,才判断为OK呢?这不是增加故障点吗? 此事询问产研,产研的答复是他们要检查的服务状态内容比较多,不是说在注册中心活着就表示服务可用,他们还要检查该服务的其他一些功能可用性,全部检查通过才会放到Redis,表明该服务对飞搭的导入/导出 功能是可用的。
另外,服务的application.yml配置中
Hzero:
apaas:
data-transport:
enable: true
这个配置的作用是什么,如果没加会产生什么影响? lowcode-data服务必须要加这个配置吗?
产研的回答是:开启数据迁移,默认就是开启的,就是你不加这个配置,默认就是true,除非你要禁止数据迁移,要加这个配置,设置为false.
所以,我们刚开始碰到的数据迁移界面上服务异常的这个问题,并非我们上面修改application.yml解决的,也不是ps-workflow服务原来依赖的parent有问题,原来依赖的是hzero-parent, 不是hzero-apaas-parent, 但也能用,没有错误,并不是这个parent的问题导致说在迁移界面显示服务异常,因为之前也是这样的没有异常,只能说是重启服务解决的,但问题的根因还未找到。只是重启相关服务是个解决方法。
问题十三、Redis TimeOut问题
正如我们在问题十所见,
Exception in thread “pool-40-thread-9” org.springframework.dao.QueryTimeoutException: Redis command timed out
这个Redis TimeOut的问题,开始在服务刚开始集中启动时,多个服务都曾经出现timeOut的问题,在不改程序的情况下,是否可以优化,豆包说:
Redis 是内存数据库,而持久化需要将内存数据写入磁盘,磁盘 I/O 速度远慢于内存,会直接带来性能损耗:
RDB 的性能影响:执行 BGSAVE 时,Redis 会 fork 子进程,这个过程会产生内存拷贝(写时复制机制),如果数据量很大,fork 操作会阻塞主进程,导致 Redis 短暂无法响应请求;子进程写入 RDB 文件时,也会占用磁盘 I/O 资源。
所以我们可以关闭Redis的持久化,提高redis的性能。
$ cp /etc/redis/redis.conf /etc/redis/redis.conf.bak20260113
$ vi /etc/redis/redis.conf
# ========== 关闭RDB持久化 ==========
# 注释掉所有以 “save” 开头的行(默认有save 900 1、save 300 10等)
# save 900 1
# save 300 10
# save 60 10000
# 新增空的save规则,彻底禁用RDB
save “”
# ========== 关闭AOF持久化 ==========
# 将appendonly设为no(默认就是no,确认即可)
appendonly no
# 可选:如果之前开启过AOF,可删除AOF文件(避免重启时加载)
# appendfilename “appendonly.aof” # 无需修改,关闭后不会写入
# ========== 可选:禁用持久化相关的后台进程 ==========
# 禁止自动生成rdb文件(防止意外触发)
rdbcompression no
rdbchecksum no
重启前执行 redis-cli FLUSHALL 命令清空所有数据
$ redis-cli FLUSHALL
$ systemctl restart redis
我们之前用的redis容器,没有挂在持久化文件,使用也正常,但却开启了持久化配置,这个就要改了,因为本身就没有做持久化挂载,还保持持久化配置就是纯浪费性能。
这个很简单,只要改下redis服务的 docker-compose.yml就好了
跟port平级,加上:
command: redis-server –save “” –appendonly no
改完重启,验证是否生效:
docker exec -it redis-hzero redis-cli config get save
root@desktop-jacksen:/d01/hzero-dockers/redis-docker# docker exec -it redis-hzero redis-cli config get save
1) “save”
2) “”
说明已经生效。
重启所有服务,逐个检查所有服务的日志,这次没看到redis 的timeout信息出现。
问题解决。
但后来在使用过程中很快发现,经用Redis持久化之后引起了其他问题,比如hzero-platform 服务日志中经常出现错误:
Caused by: io.lettuce.core.RedisCommandTimeoutException: Command timed out after 5 second(s)
界面操作时不时会出现:504 GATEWAY_TIMEOUT “Response took longer than timeout: PT20S”
所以还是把持久化恢复吧:
$ cp /etc/redis/redis.conf.bak20260113 /etc/redis/redis.conf
$ systemctl restart redis
然后需要重启hzero-platform服务
#Docker 环境改成持久化
$mkdir -p /d01/hzero-dockers/volumes/redis/{data}
$chmod 777 /d01/hzero-dockers/volumes/redis/data
#docker-compose.yml中注释掉去持久化配置:
#command: redis-server –save “” –appendonly no
#挂载data目录
volumes:
# 映射数据目录(持久化文件存储位置,核心)
– ${DOCKER_VOLUME_DIRECTORY:-../volumes}/redis/data:/data
持久化恢复也有问题,后来在使用的时候,发现各模块经常会频繁的redis timeout问题,导致系统运行非常卡,默认每5分钟会全量保存持久化一次,太频繁了,后来就改成一小时保存一次。这可以在redis容器的docker-compose.yml中配置:command: redis-server –save 3600 1 –save “”
## 要求Docker/Docker CE >= 19.x
services:
redis-hzero:
image: redis:6-alpine
container_name: redis-hzero
ports:
– “6379:6379”
volumes:
# 映射数据目录(持久化文件存储位置,核心)
– ${DOCKER_VOLUME_DIRECTORY:-../volumes}/redis/data:/data
#command: redis-server –save “” –appendonly no
command: redis-server –save 3600 1 –save “”
deploy: # 限制容器总内存(Docker Compose v2.3+)
resources:
limits:
memory: 1000m # 容器最大内存
networks:
default:
name: hzero-demo
external: true
由于是笔记本上WSL虚拟机,我后来发现redis time out的问题不仅仅是这个持久化写的频率问题, 笔记本的电源计划在某天升级Windows后变成了节能模式,在接通电源情况3分钟就休眠,这也是导致各服务卡顿的主要问题。后来就更改了电源计划,在接通电源的模式下改成永不休眠。 卡顿的问题就得到了改善。
另外就是,在碰到前端报gateway timeout错误,在gateway服务中看到 TimeOut错误是调用platform服务导致的等待超时,这种情况可能是重启了redis而没有重启platform服务导致的,在重启platform服务之后可以解决这种卡顿问题。
问题十四:资源分配问题还是OpenJ9 JVM的稳定性问题?
进入流程平台工作台,报hzero-lowcode服务不可用。
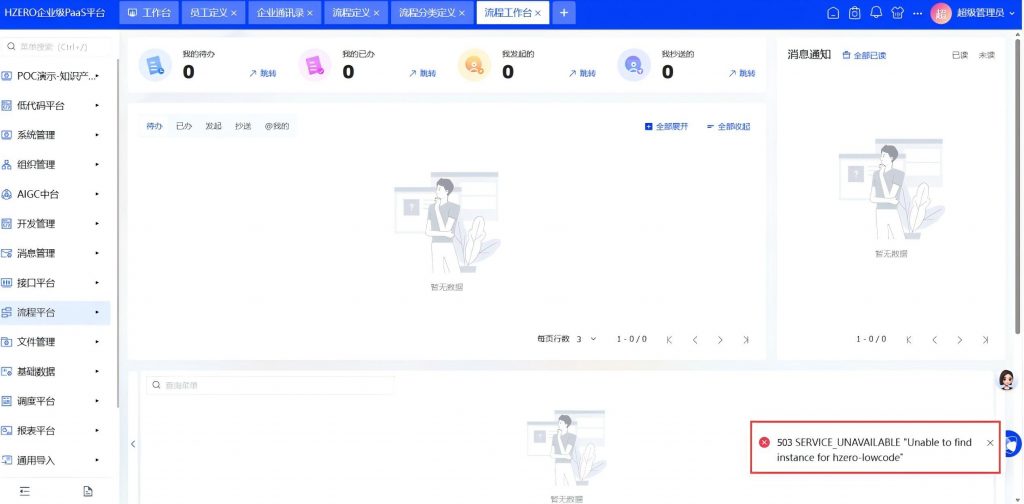
分析,查hzero-lowcode服务的日志:
Caused by: org.springframework.beans.factory.UnsatisfiedDependencyException:
Error creating bean with name ‘externalInvokeAdvisor’:
Unsatisfied dependency expressed through field ‘advice’:
… [嵌套异常链] …
Caused by: org.springframework.beans.factory.NoSuchBeanDefinitionException:
No bean named ‘org.springframework.context.annotation.ConfigurationClassPostProcessor.importRegistry’ available
元宝分析:总而言之,当前服务掉线是由于Spring容器在初始化时因配置或依赖问题而无法启动,并非运行中的崩溃。您的排查重点应放在 依赖版本兼容性 和 配置类/Bean的加载顺序 上。从日志末尾的EurekaDiscoveryClient来看,这个问题可能与服务注册发现相关的配置有关联。
我之前遇到这种问题是重启解决的,我还是重启一下:结果
有这个错误:
Error starting ApplicationContext. To display the condition evaluation report re-run your application with ‘debug’ enabled.
2026-01-16T06:00:58.870Z ERROR 1 — [hzero-lowcode] [ main] o.s.boot.SpringApplication : Application run failed
org.springframework.beans.factory.BeanCurrentlyInCreationException: Error creating bean with name ‘observationRestTemplateCustomizer’: Requested bean is currently in creation: Is there an unresolvable circular reference or an asynchronous initialization dependency?
at org.springframework.beans.factory.support.DefaultSingletonBeanRegistry.beforeSingletonCreation(DefaultSingletonBeanRegistry.java:421) ~[spring-beans-6.2.1.jar!/:6.2.1]
at org.springframework.beans.factory.support.DefaultSingletonBeanRegistry.getSingleton(DefaultSingletonBeanRegistry.java:282) ~[spring-beans-6.2.1.jar!/:6.2.1]
at org.springframework.beans.factory.support.AbstractBeanFactory.doGetBean(AbstractBeanFactory.java:334) ~[spring-beans-6.2.1.jar!/:6.2.1]
元宝分析:问题根源:循环依赖
错误信息 BeanCurrentlyInCreationException和 Is there an unresolvable circular reference?明确指出了问题的核心:Spring 容器在初始化 Bean 时,发现它们之间存在直接的或间接的循环引用关系 。
简单来说,这就像几个团队项目互相“卡脖子”:Bean A的创建需要先有 Bean B,而 Bean B的创建又反过来需要先有 Bean A。Spring 容器无法决定谁应该先被创建,从而陷入死锁,最终抛出异常并导致应用启动失败 。
在您这个案例中,问题直接指向了 observationRestTemplateCustomizer这个 Bean。从 Bean 的名称推测,它很可能与 Spring Boot 的应用监控功能(可能是 Micrometer 或相关组件)相关。这个 Bean 在创建过程中,与另一个或多个 Bean 形成了这种循环依赖。
这有无可能是IBM OpenJ9 Jvm的问题?
OpenJ9 和 HotSpot 是两种不同的 JVM 实现,它们在类加载、内存管理和即时编译(JIT)策略上存在差异 。这些底层实现的区别,可能导致 Spring 容器初始化 Bean 的顺序和时机发生微妙的改变。
具体来说,有实践表明,在由 HotSpot 迁移至 OpenJ9 时,可能会遇到一些兼容性问题。例如,某公司在实践中发现,OpenJ9 在类加载机制、内存使用模式等方面与 HotSpot 存在差异,这有时会导致一些在 HotSpot 上运行良好的应用在 OpenJ9 上出现异常 。您的情况很可能类似:之前隐藏在 HotSpot 下的循环依赖,在 OpenJ9 不同的初始化时序下被提前触发了 。
简单来说,这就像两个仓库管理员(HotSpot 和 OpenJ9)用不同的方法整理货物(Bean)。可能有一种方法能勉强把有问题的货物塞进仓库,而另一种更“较真”的方法则会立刻发现货物尺寸不匹配而卡住。
按照错误日志第一行的建议,使用 –debug参数重启应用(例如 java -jar your-app.jar –debug)。Spring Boot 会打印出一份非常详细的条件评估报告,其中会清晰列出形成循环依赖的完整 Bean 链条,这是解决问题的关键第一步 。
这个麻烦了,需要该服务的开发者调试。不是我们该干的事。
我还是停掉服务,不要马上重启,过一段时间再重启,结果启动成功了,没有报上面的这种错误。
疑问:是否可以说OpenJ9的JVM不稳定,仅使用于个人实验环境,因为可以通过重启服务解决,但也就是个人实验环境适合这么干?
产研认为不太可能是OpenJ9的稳定性问题,因为外面有很多商业项目也在用OpenJ9,更可能是资源问题;那我再看下资源消耗:
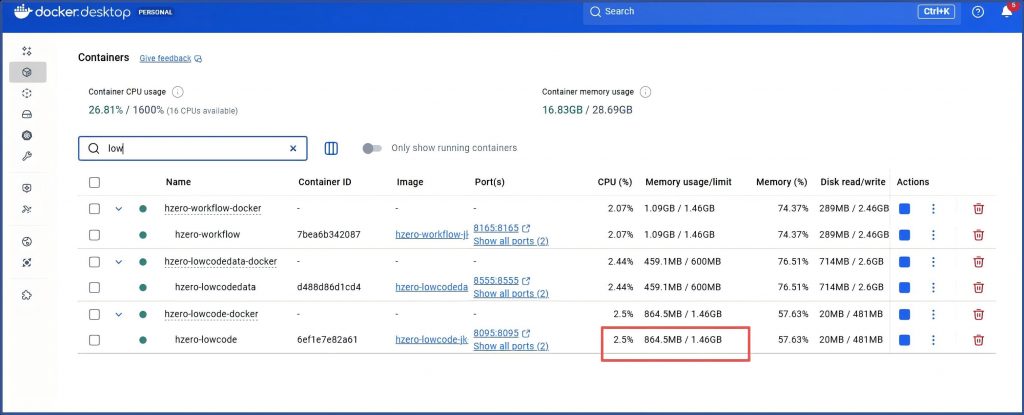
内存消耗目前已经到了864M
我们在docker-compose.yml中分配的max内存是800M,资源非配确实有问题。
– JAVA_OPTS=-Xms128m -Xmx800m -Dspring.profiles.active=dev
那我们继续做实验,把xmx 调整到600M,再启动,果然又出现之前的bean创建不了的情况了。
#继续实验,把xmx 调整到1000M,再启动,结果启动成功了,没有报上面的那些Bean创建失败的错误。
#继续实验,把xmx 再次调整到600M, 再启动,结果居然也成功启动了,那这个成功启动是不是之前设置为1000M的时候的缓存还在,导致能成功启动的?
#继续实验,关闭服务之后等一会再以xmx=600M 启动,等了大概5分钟后再重启,结果居然也成功了。
那暂时似乎也不能说是资源问题。
问题十五、工作流模拟启动时报错:流程版本未生效!
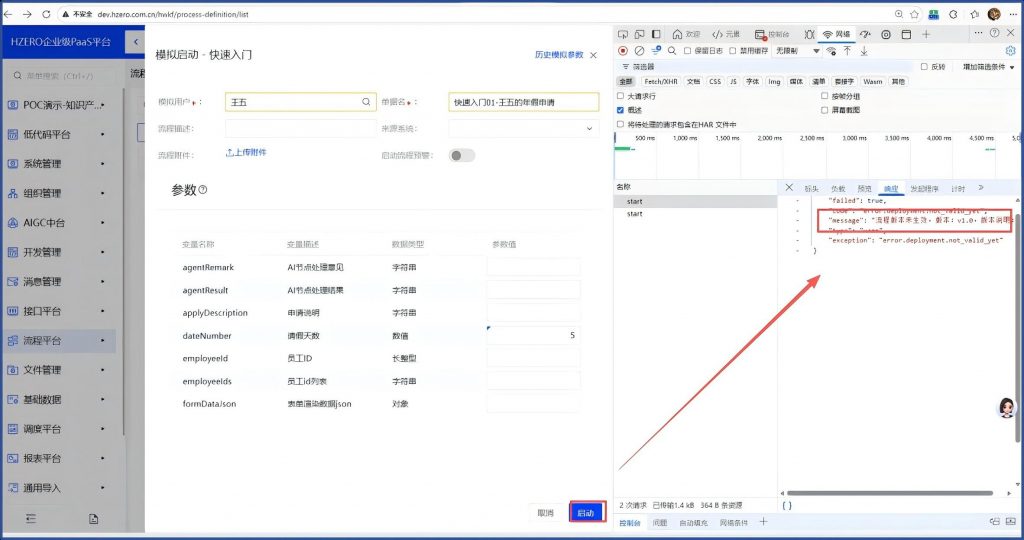
分析:查hzero-workflow服务日志,错误信息如下:
2026-01-16T08:26:02.546Z INFO 1 — [hzero-workflow] [ool-3-thread-10] org.hzero.core.util.CommonExecutor : [>>ExecutorStatus<<] ThreadPool Name: [bean-searcher], Pool Status: [shutdown=false, Terminated=false], Pool Thread Size: 0, Largest Pool Size: 0, Active Thread Count: 0, Task Count: 0, Tasks Completed: 0, Tasks in Queue: 0
2026-01-16T08:26:05.457Z WARN 1 — [hzero-workflow] [ XNIO-1 task-7] o.h.core.exception.BaseExceptionHandler : Common exception, Request: {URI=/v1/2/monitor-simulate/start}, User: CustomUserDetails{userId=2, username=admin, roleId=10, roleIds=[10], siteRoleIds=[], tenantRoleIds=[10], roleMergeFlag=false, secGrpIds=[], tenantId=2, tenantIds=[2, 0], organizationId=0, isAdmin=true, clientId=null, timeZone=’GMT+9, language=’zh_CN, roleLabels='[TENANT_ADMIN], apiEncryptFlag=1}
io.choerodon.core.exception.CommonException: error.deployment.not_valid_yet
at org.hzero.workflow.engine.run.impl.ModelServiceImpl.checkValid(ModelServiceImpl.java:656) ~[hzero-workflow-1.20.0-1.12.RELEASE.jar!/:1.20.0-1.12.RELEASE]
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[na:na]
元宝分析可能原因:
依赖版本冲突
在某些情况下,如果项目依赖的库(如 MyBatis-Plus, jsqlparser 等)版本不兼容,可能会在运行时抛出 NoSuchMethodError或 NoClassDefFoundError,最终被包装为 Handler dispatch failed异常
问了产研
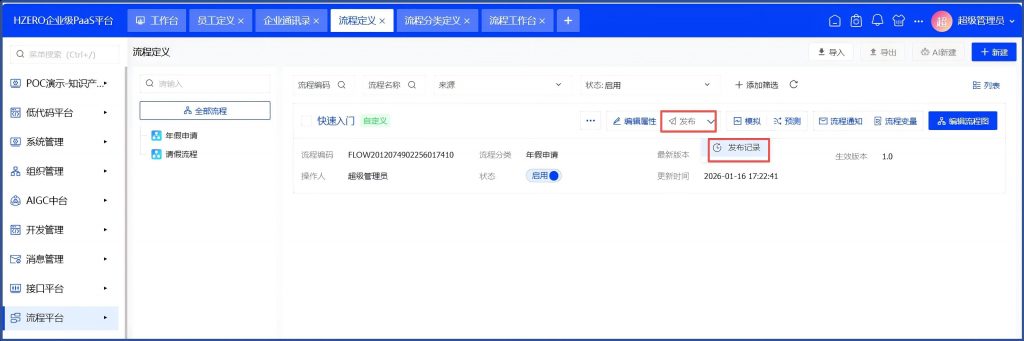
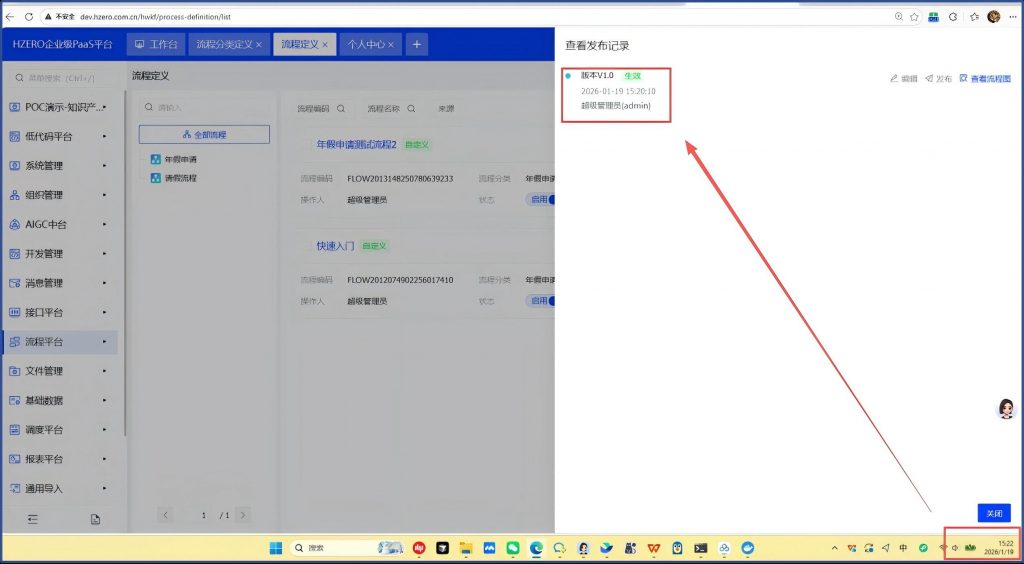
看到发布记录中生效时间是一小时后。 再发布一个版本,看默认是当前时间:
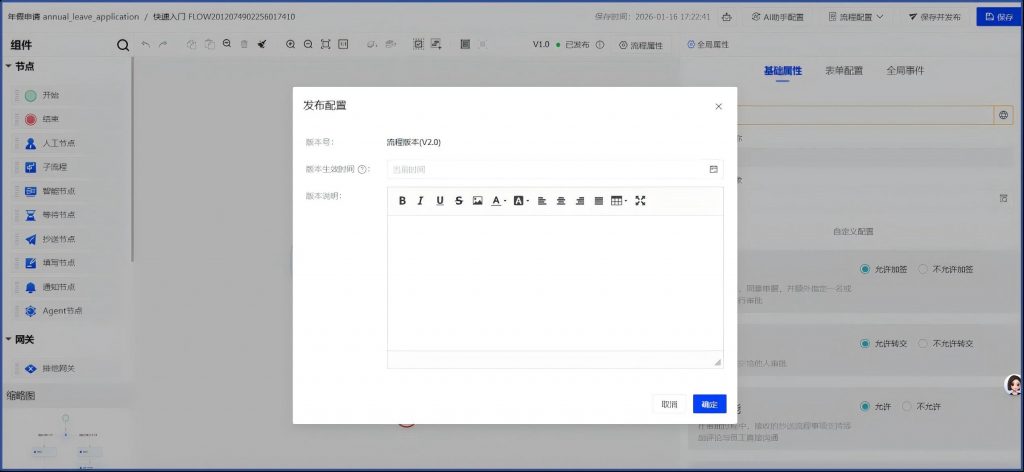
这次看生效时间默认还是一小时后。当前时间是16:41
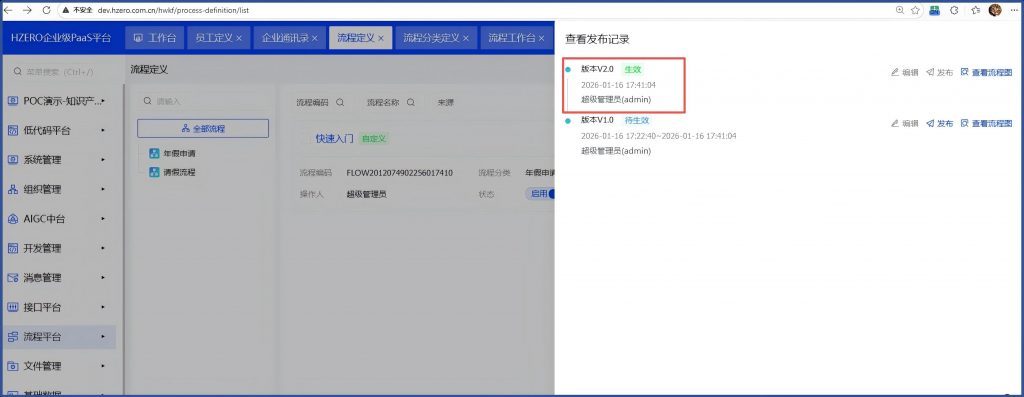
如果没特意配置,可能是系统时间有问题:
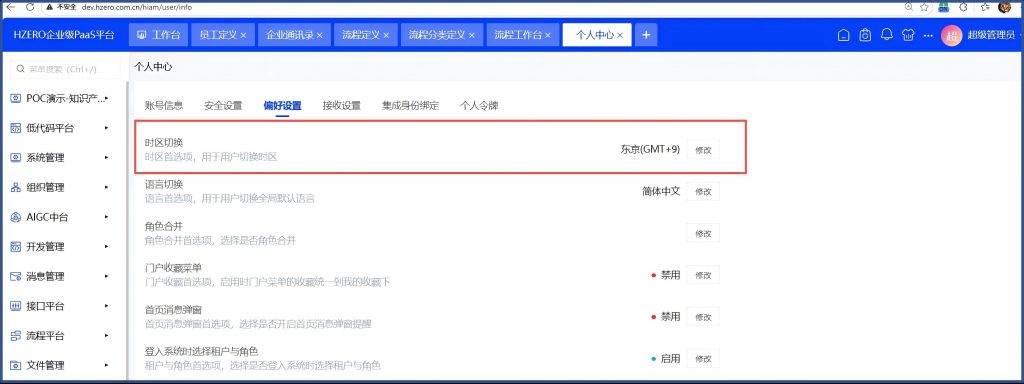
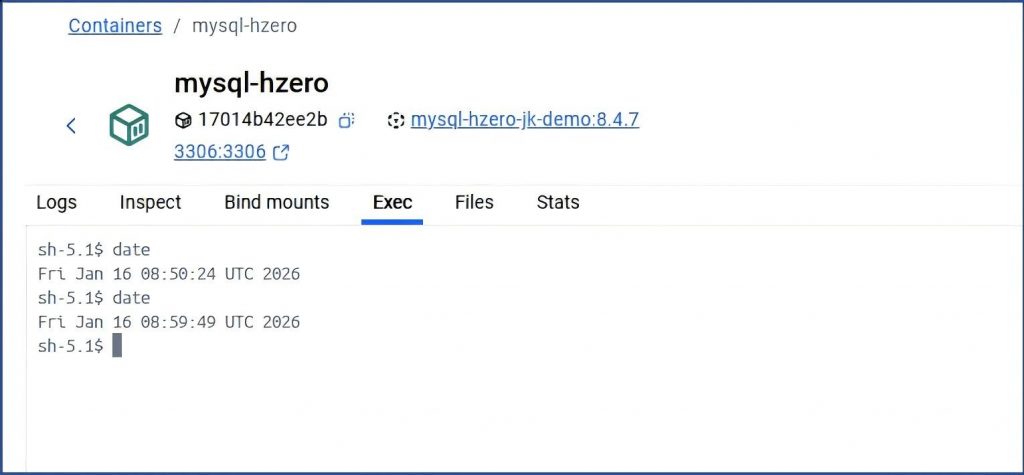
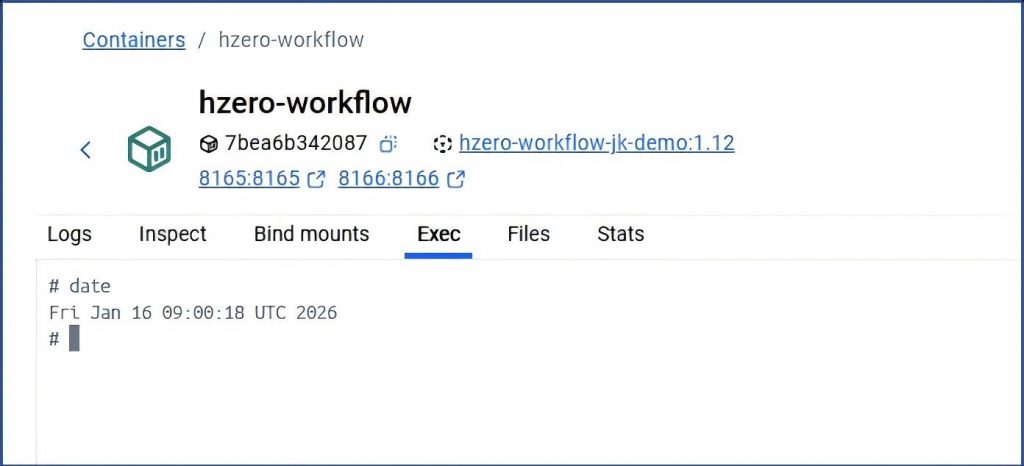
个人中心把时区改成北京时区再发布一下:这次一致了:
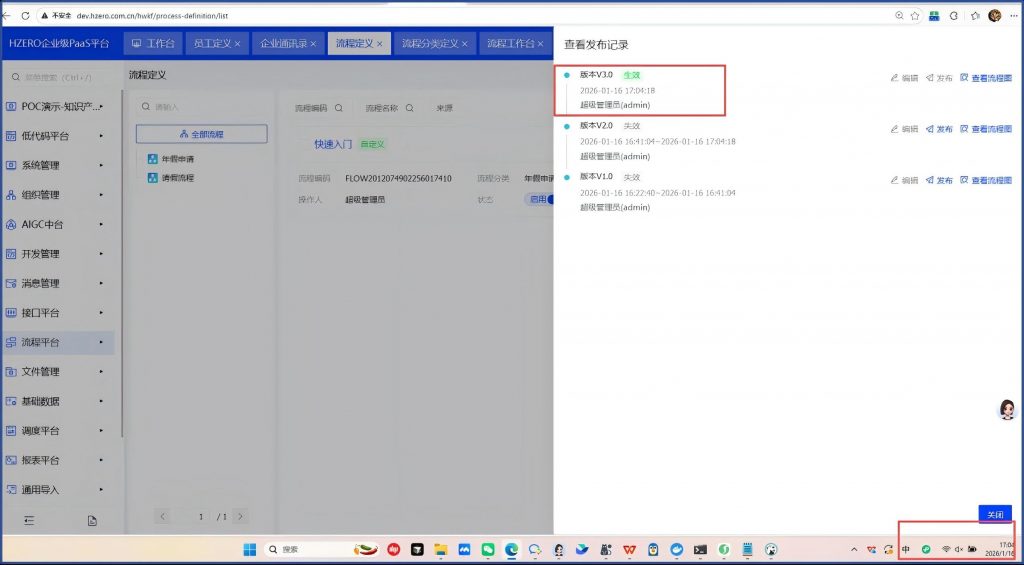
但模拟还是不行:
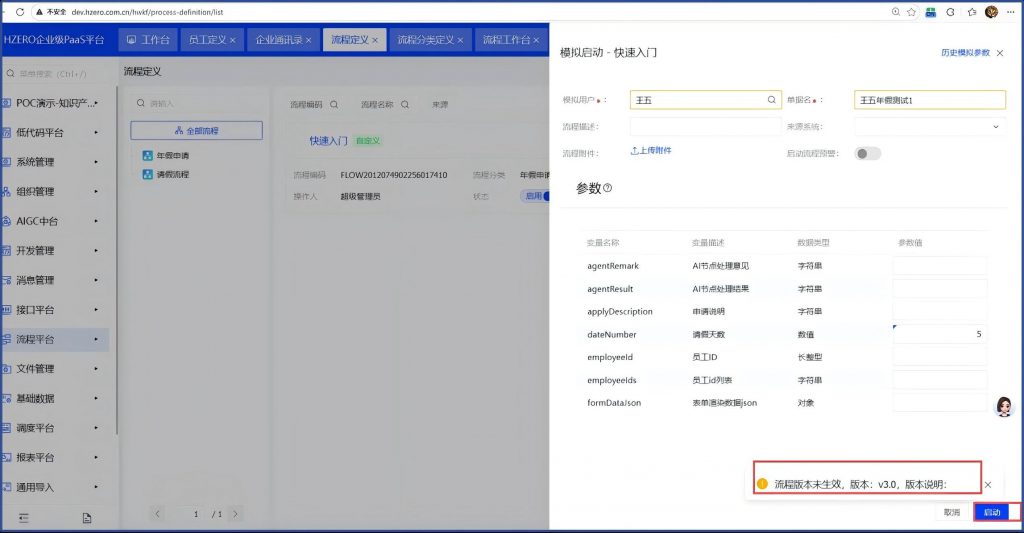
修改个人中心的时区之后,在重新建一个工作流:年假申请测试流程2,再测试:
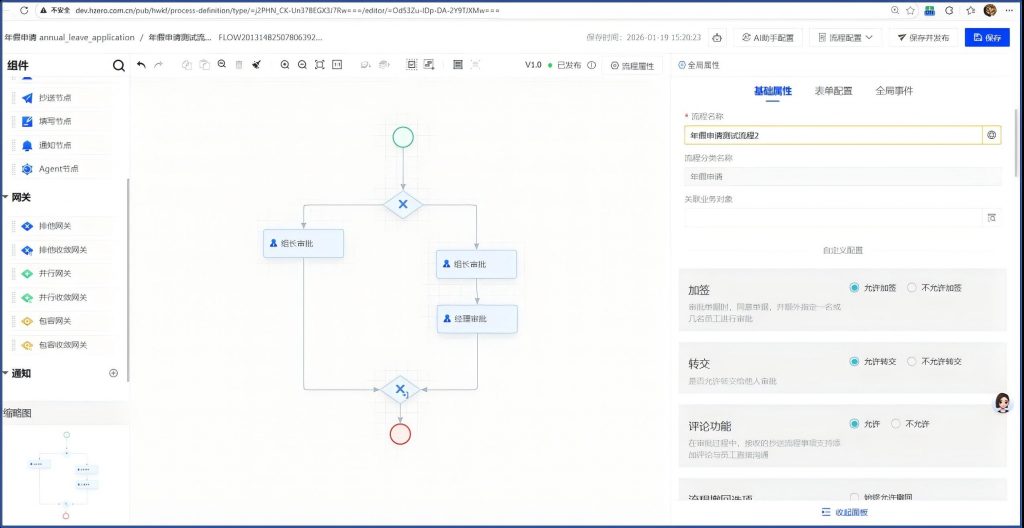
建好后,保存发布,看到生效时间立即生效是对的:
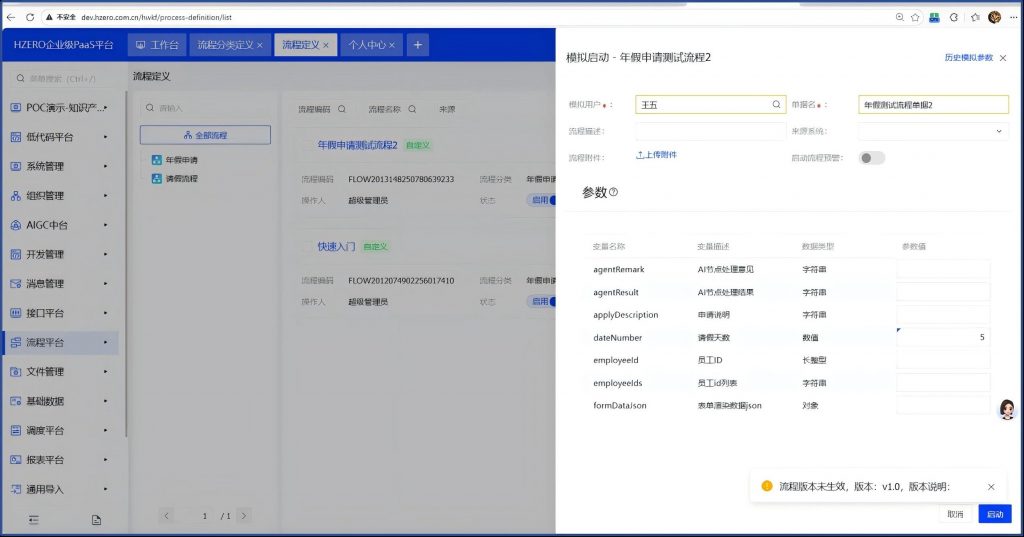
再次点“模拟” ,还是不行,没法马上模拟成功,要过一天才能模拟:
当前的hzero-workflow 是1.20-1.12.RELEASE的,是25年7月发的版,最新更新已经到了 1.20.1-1.12-BETA.8 是25年12月24日,期间补丁版本已经发了8个了;
升级到1.20.1-1.12-BETA.8 问题依旧。
产研时区问题后来解决了,发了新的版本,需要升级:
=============================================
2026-01-28 升级HZERO 工作流 从1.20.0-1.12.RELEASE 到 1.20.1-1.12.RELEASE
=============================================
升级原因:解决流程平台编辑流程后模拟运行时因为时区设置差异导致 不能立即执行的问题。
1、升级种子数据
再次下载:hwkf-resource-1.20-1.12.RELEASE.zip(产研说因为这个修复版加上了咸亨的部分需求,与数据库字段变更,所以要跑下种子数据:表结构和种子数据)
解压后启动脚本,启动完成后 ,在界面上 执行 1和3 成功完成。
2、升级后端服务
hzero-workflow@1.20.1-1.12.RELEASE
更新POM,然后重新bash run.sh 服务启动正常。
3、升级前端组件
hzero-front-hwkf@1.20.2-beta.1
hzero-front-hwkf-mobile@1.20.1-beta.8
更新package.json
yarn
Done in 45.28s.
yarn run build:ms hzero-front-hwkf,hzero-front-hwkf-mobile
Done in 223.22s
完成后执行部署:
$ bash apply_update_to_runtime_env.sh
cp \\wsl.localhost\Ubuntu-2204-hzero-openjdk\d02\hzero-bpaas\project\ps-workflow\target\ps-workflow.jar \\wsl.localhost\Ubuntu-22.04\d01\hzero-dockers\hzero-workflow-docker\
重新构建镜像
拷贝前端文件到Docker环境:
$ cp -r -Force \\wsl.localhost\Ubuntu-2204-hzero-openjdk\d02\hzero\front\dist \\wsl.localhost\Ubuntu-22.04\d01\hzero-dockers\volumes\nginx\
#拷贝种子数据到Docker环境:
cp \\wsl.localhost\Ubuntu-2204-hzero-openjdk\d02\hzero-bpaas\hwkf-resource\hwkf-resource-1.20-1.12.RELEASE.zip \\wsl.localhost\Ubuntu-22.04\d01\tmp\
#Docke环境启动mysql容器
/d01/hzero-dockers/mysql-docker# docker compose up -d
cd /d01/tmp
unzip hwkf-resource-1.20-1.12.RELEASE.zip
cd hwkf-resource-1.20-1.12.RELEASE
bash database-init.sh执行1和3,完成种子数据更新
再测测试,时区正常了,模拟可以正常立即执行了。问题解决。