
基于 Karpathy 提出的”LLM编译器”理念,用 OpenClaw + Obsidian 构建 HZERO PaaS 平台知识库
背景
Andrej Karpathy 曾提出一个观点:LLM 不是搜索引擎,而是编译器——将原始资料编译成结构化知识。
这个理念启发我构建了 HZERO-wiki 知识库。区别于传统的”检索式”知识库,HZERO-wiki 采用编译器模式:
raw/ 是唯一事实源:原始资料只存放,不修改
wiki/ 是编译产物:LLM 自动提炼、结构化、建立链接网络
增量更新机制:避免每次全量扫描,只处理新增/修改文件
一、文件夹结构及作用
HZERO-wiki 采用三层架构,借鉴软件编译流程:
HZERO-wiki/
├── raw/ # 【原材料层】唯一事实源
│ ├── 平台产品介绍/ # 官方产品介绍 PPT/PDF
│ ├── 平台产品项目案例/ # 项目案例文档
│ ├── 平台产品开发文档/ # 技术开发文档
│ └── .processed_files.json # 处理日志(增量核心)
│
├── wiki/ # 【知识层】LLM 编译产物
│ ├── HZERO PaaS平台.md
│ ├── aPaaS低代码平台-飞搭.md
│ ├── bPaaS流程平台-班翎.md
│ ├── iPaaS集成平台-集星獭.md
│ ├── gPaaS基础管理平台-鲲苍.md
│ ├── AMPaaS应用管理平台-零衍.md
│ ├── H-AI灵猿AI中台.md
│ ├── H-AI灵炼.md
│ ├── H-AI飞码.md
│ ├── 移动技术平台-海马汇.md
│ ├── 行狼监控运维平台.md
│ ├── 汉得数字化平台.md
│
├── schema/ # 【规则层】LLM 契约
│ ├── CLAUDE.md # 处理规则(摄入/编译/lint/查询)
│ └── TERM_MAPPING.md # 术语标准化映射表
│
└── .trash/ # 废弃文件回收站三层架构说明
层级 作用 特点
raw/ 原材料层 存放原始资料(PPT/PDF/DOCX/图片) 唯一事实源,永不修改
wiki/ 知识层 LLM 编译产出的结构化词条 Obsidian 兼容,双向链接网络
schema/ 规则层 定义 LLM 如何处理 raw → wiki 人工维护,LLM 遵守
二、三个核心文件的作用
2.1 .processed_files.json — 增量处理日志
位置: raw/.processed_files.json
作用: 记录已处理文件的哈希、修改时间、大小,实现增量更新,避免每次全量扫描。
文件结构示例:
{
"平台产品介绍/汉得H-ZERO PaaS平台简介V1.pptx": {
"hash": "762889f06fe03a37a1b35c09645c8e9243806f75a5d7abc747db49ac4be25ca5",
"mtime": 1773034858,
"size": 3991781,
"processed": "2026-05-22"
}
}工作原理:
Ingest 阶段扫描 raw/ 目录
对比 .processed_files.json:
新增文件 → 处理
修改文件(mtime/hash 变化)→ 重新处理
未变更文件 → 直接跳过
处理完成后更新日志
意义: 知识库从 12 个文件扩展到 100+ 个时,每次增量只需处理新增内容,不会重复处理已编译的文件。
2.2 CLAUDE.md — LLM 处理规则
位置: schema/CLAUDE.md
作用: 定义 LLM 如何将 raw/ 编译成 wiki/,是整个知识库的编译规则契约。
核心规则摘录:
## 总体原则
1. **raw/ 是唯一事实源**:永远不修改 raw 下任何原始文件
2. **严格增量处理,禁止每次全量扫描**:通过 .processed_files.json 识别新增文件
3. 禁止幻觉:不确定标注 [UNCERTAIN],冲突标注 [CONFLICT]
4. 所有词条使用 Obsidian 兼容 Markdown,自动生成 [[内部链接]]
## OpenClaw 行为强制规则
### Ingest 摄入阶段
1. 读取 .processed_files.json,识别已处理文件
2. 扫描 raw 文件夹(仅一级子目录)
3. 新增文件 → 处理;未变更文件 → 跳过
4. 处理完成后更新 .processed_files.json
### Compile 编译阶段
- 只更新增量文件对应的 wiki 词条
- 自动合并重复概念、补全双向链接
### Lint 自检阶段
- 清理无效链接、统一术语、合并重复词条词条固定结构:
---
title: HZERO PaaS平台
tags: [PaaS, 数字化底座]
source: raw/平台产品介绍/汉得H-ZERO PaaS平台简介V1.pptx
updated: 2026-05-22
---
## Summary(100-200字核心概括)
## Core Content(图文融合,OCR嵌入上下文)
## Related Concepts(双向链接:[[aPaaS]] [[bPaaS]])
## Conflicts & Uncertainties(标注待确认项)
## Sources(引用来源)2.3 TERM_MAPPING.md — 术语标准化映射表
位置: schema/TERM_MAPPING.md
作用: 解决原始资料中术语混乱问题,确保 wiki 中术语唯一、统一。
问题场景:
同一产品在 PPT 中有多种写法:
H-ZERO-PaaS平台
hzero-paas-platform
H0 PaaS platform
H0-PaaS平台
如果不统一,LLM 会生成多个重复词条,双向链接失效。
映射表格式:
## 格式规范
【标准术语】|【别名1,别名2,别名3】
## 已收录术语
HZERO PaaS平台|H-ZERO-PaaS平台,hzero-paas-platform,H0 PaaS platform
bPaaS流程平台-班翎|BPaaS流程平台,bpaa-s流程平台-班翎,班翎
aPaaS低代码平台-飞搭|aPaaS低代码平台,apaas低代码平台-飞搭,飞搭工作原理:
LLM 处理 raw 文件前,强制先读取 TERM_MAPPING.md
遇到任何术语变体 → 自动替换为标准术语
wiki 中只出现标准术语,杜绝重复词条
维护原则: 仅人工维护,AI 禁止直接修改。
三、wiki-ingest 技能的作用
为了让所有 AI 代理都能执行增量摄入流程,我创建了一个 wiki-ingest Skill。
3.1 Skill 的优势
维度 MEMORY.md 固化规则 wiki-ingest Skill
作用范围 仅当前代理(main session) 所有代理全局可用
加载时机 每次会话自动加载 触发时按需加载
适用场景 强化提醒当前代理 任何代理都能执行
3.2 触发方式
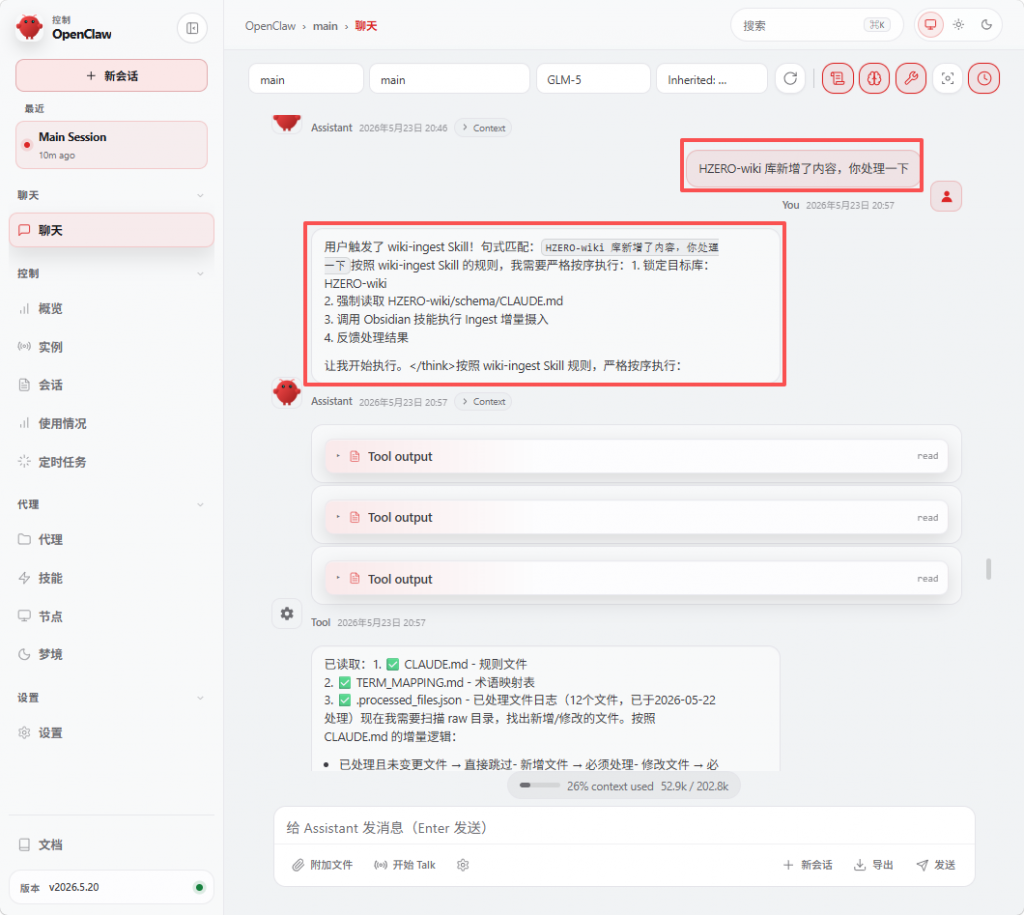
触发句式:
HZERO-wiki库新增了内容,你处理一下
openclaw, 小龙虾-wiki知识库新增了内容,你处理一下3.3 执行流程(严格按序)
锁定目标库 → 提取库名 XXX,目标库为 XXX-wiki
强制读取规则 → XXX-wiki/schema/CLAUDE.md
调用 Obsidian 技能 → 执行 Ingest 增量摄入
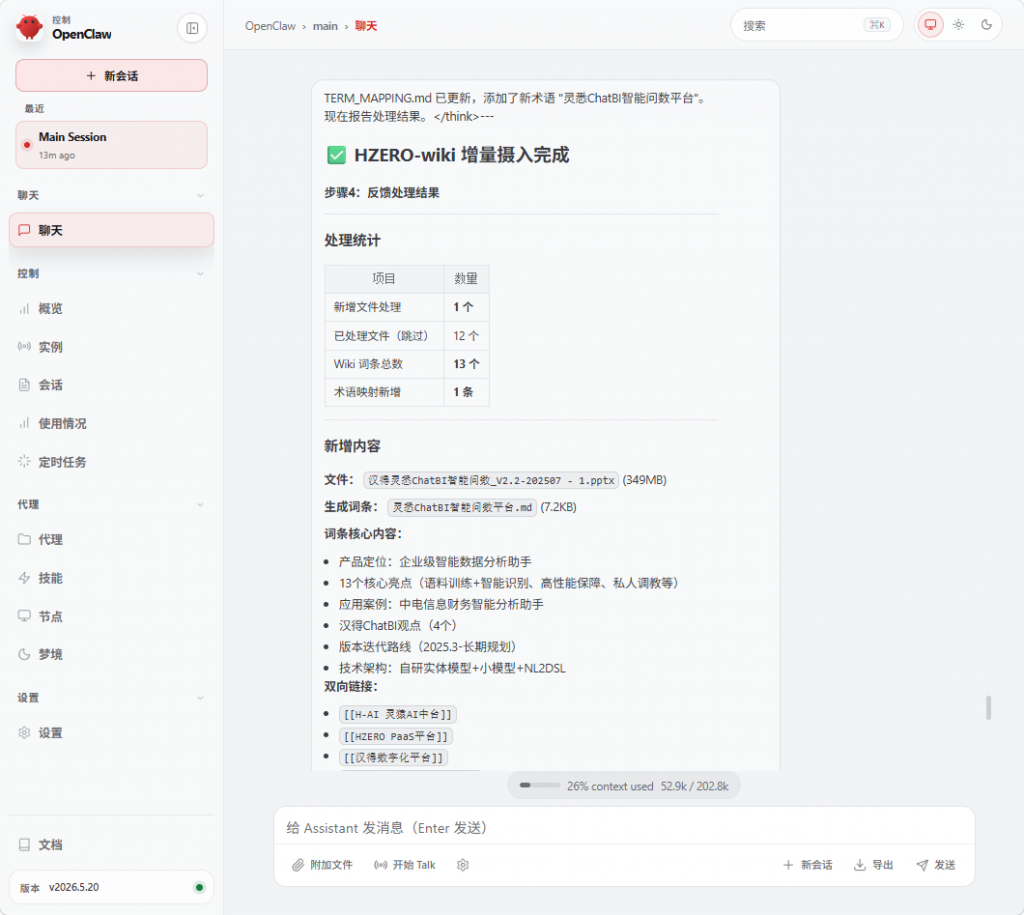
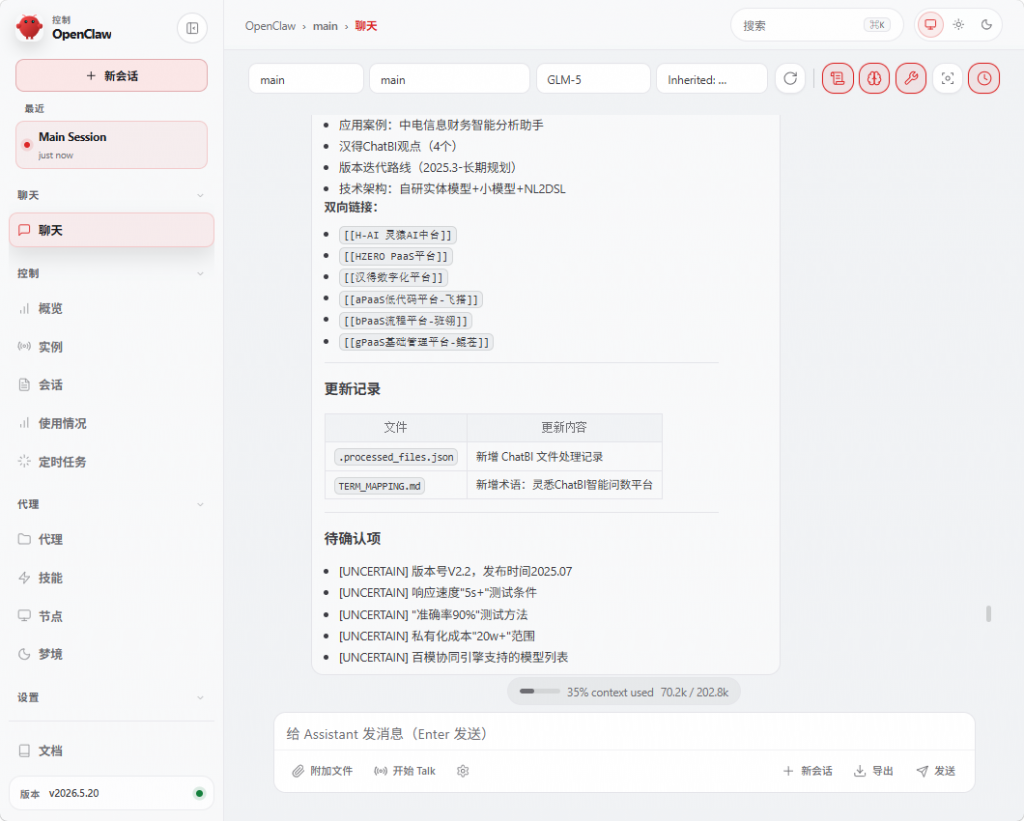
反馈处理结果 → 报告处理文件数、新增词条、待确认项
异常处理: 找不到 CLAUDE.md → 立即提醒用户,停止执行。
3.4 Skill 文件结构
~/.openclaw/skills/wiki-ingest/
SKILL.md # 触发规则 + 执行步骤 + 异常处理四、实践总结
知识库成果
指标 数量
原始资料 12 个 PPTX(622MB)
Wiki 词条 12 个(52KB)
双向链接 68 个
待确认项 24 个 [UNCERTAIN]
核心价值
增量更新机制:知识库扩展到 100+ 文件时,每次只需处理新增内容
术语统一:TERM_MAPPING.md 杜绝重复词条,Obsidian 双向链接有效
全局能力:wiki-ingest Skill 让所有代理都能执行摄入流程
编译器理念:raw 是事实源,wiki 是编译产物,规则是契约
下一步计划
补充 OCR 内容(iPaaS、AMPaaS 关键图片)
扩展 raw 目录(项目案例、开发文档)
测试:
参考资料
OpenClaw 文档:https://docs.openclaw.ai
Obsidian 官方网站:https://obsidian.md
Karpathy LLM 编译器理念:编译而非检索
本文介绍的是基于 OpenClaw + Obsidian 构建的知识库实践方案,核心思想来源于 Karpathy 的”LLM 编译器”理念。