更新向量模型之后如何成功重建索引
作者:H0总助 | 文档版本:V1.0 | 适用平台:HZERO AIGC平台 1.6.1
一、引言
在HZERO AIGC平台的使用过程中,有时需要更换底层向量模型。例如原来使用的是豆包的向量模型 doubao-embedding-large-text-250515,现在要切换到阿里的 text-embedding-v4。切换完成后,文档库中已有的文档需要重建向量索引,才能让知识问答功能继续正常工作。
本文档详细记录了从切换向量模型到成功重建索引的完整操作步骤,包括过程中可能遇到的两个典型报错及其解决方法,供益吉的海森以及其他遇到类似问题的同学参考。
二、背景:为什么要换向量模型
原先系统中使用的豆包向量模型 doubao-embedding-large-text-250515 已无法使用(豆包已不再提供纯文本向量模型服务),因此需要切换到阿里的文本向量模型 text-embedding-v4。
切换流程大致如下:
在模型对接配置中新建阿里 text-embedding-v4 对接账户
在模型组合配置中创建新的向量组合(如”Jack文本向量组合-阿里”),关联阿里向量模型
在全局选项配置中,将默认文本向量模型改为新建的组合
删除旧的向量索引,然后重建
三、第一步:准备新的向量模型对接
这是最基础的一步,但有一个容易忽略的细节:向量维度。
3.1 确认向量模型的维度
不同的向量模型输出的向量维度是不同的:
| 向量模型 | 输出维度 | 说明 |
| doubao-embedding-large-text-250515 | 2048 | 豆包旧版纯文本向量模型,已停止服务 |
| text-embedding-v4(阿里) | 1024 | 阿里当前最新文本向量模型 |
| doubao-embedding-vision(豆包) | 多种可选 | 豆包新版图文向量模型 |
如果你的旧索引是用 2048 维度建的,现在换成了 1024 维度的模型,那重建索引时就会报错(见第五节)。
3.2 在值集中添加新维度(如果需要的话)
新建模型对接账户时,当你选择了”向量-阿里”这个模型类型后,系统要求你选择一个维度值。如果下拉菜单中找不到 1024 这个选项,说明值集中没有这个维度的配置。
操作路径:
系统管理 > 值集管理 > 搜索”向量模型维度”(或类似名称) > 在值集值列表中添加一条新记录,值填写 1024,含义填写”阿里向量模型维度”或其他便于识别的名称。
添加完成后回到模型对接配置页面,刷新后 1024 就会出现在下拉选项中了。
3.3 新建模型对接账户
在”模型对接配置”页面,点击”新建”按钮,填写以下信息:
| 字段 | 填写内容 | 说明 |
| 账户编码 | JACK-TEXT-EMBEDDING-ALI | 自定义,建议有意义的命名 |
| 模型分类 | 向量-阿里 | 选择阿里文本向量模型分类 |
| 模型类型 | text-embedding-v4 | 选择对应的阿里模型 |
| 维度 | 1024 | 选择刚添加到值集中的维度 |
| ak/sk等凭证 | 根据实际情况填写 | 阿里云的API访问凭证 |
配置完成后点击”测试”按钮,确认返回正确的向量值,表示对接成功。
3.4 创建新的模型组合
在”模型组合配置”页面,点击”新建”:
– 组合名称:例如 “Jack文本向量组合-阿里”
– 模型角色:文本向量
– 策略选择:轮询(如果有多个模型需要均衡)或优先级
– 关联模型:选择刚才新建的阿里向量模型对接账户
创建完成后点击”测试”,验证组合可用。
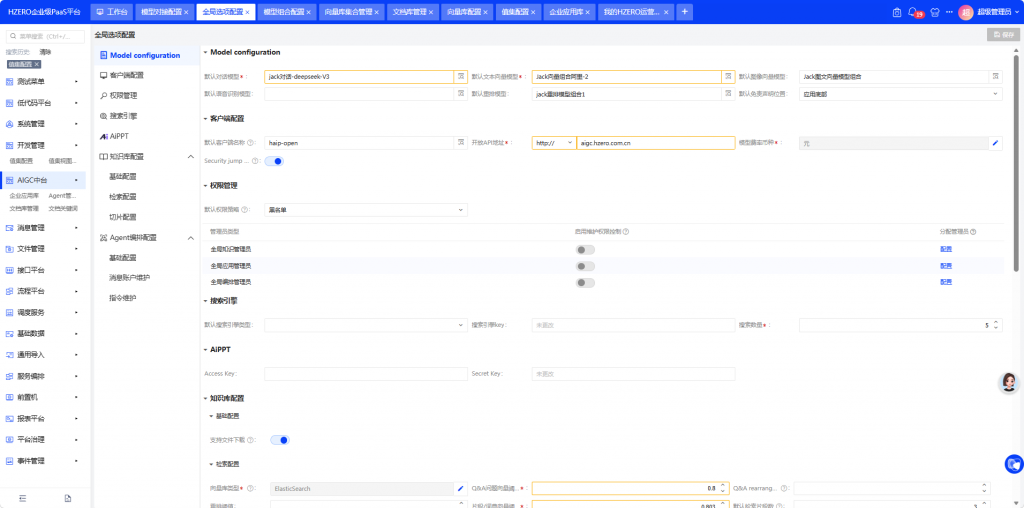
3.5 设置为默认文本向量模型
在”全局选项配置”页面,找到”默认文本向量模型”配置项:
点击编辑,将原来的默认向量组合改为刚创建的”Jack文本向量组合-阿里”
保存并确认弹窗
四、第二步:清理旧索引并重建
换了向量模型后,旧的索引映射(mapping)依然保持着旧模型的维度设定(如2048),与新模型(1024)不匹配。因此需要清理旧索引,让系统重新创建。
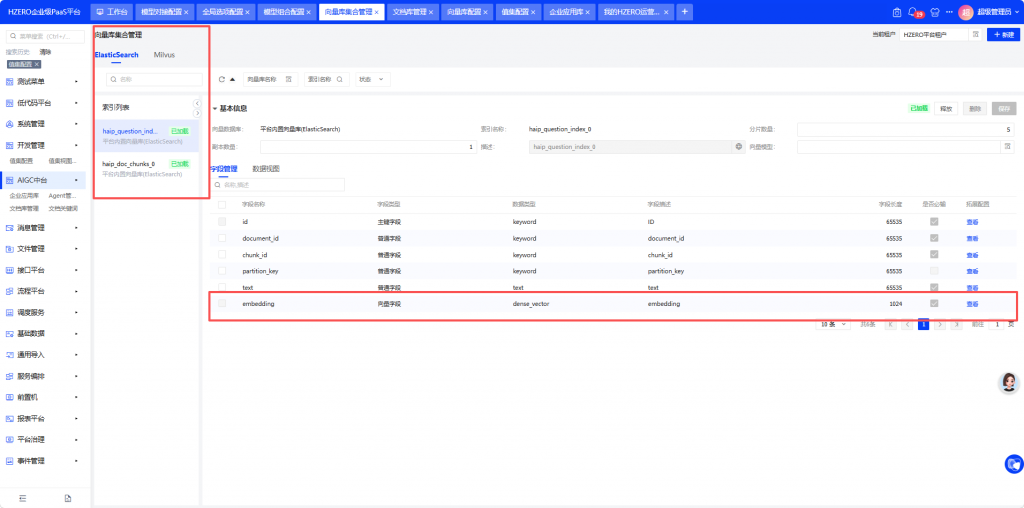
4.1 查看并释放旧索引
在”向量库集合管理”页面,可以看到所有已有的索引,通常包括:
haip_doc_chunks_0 文档索引
haip_question_index_0 问题索引
haip_dictionary_value_0 词典索引
haip_feature_word_0 特征词索引
haip_summary_index_0 摘要索引
逐个点击操作列的”释放”按钮释放索引。释放后索引会出现在底部列表中,再点击”删除”彻底移除。注意:释放和删除是两步操作,缺一不可。
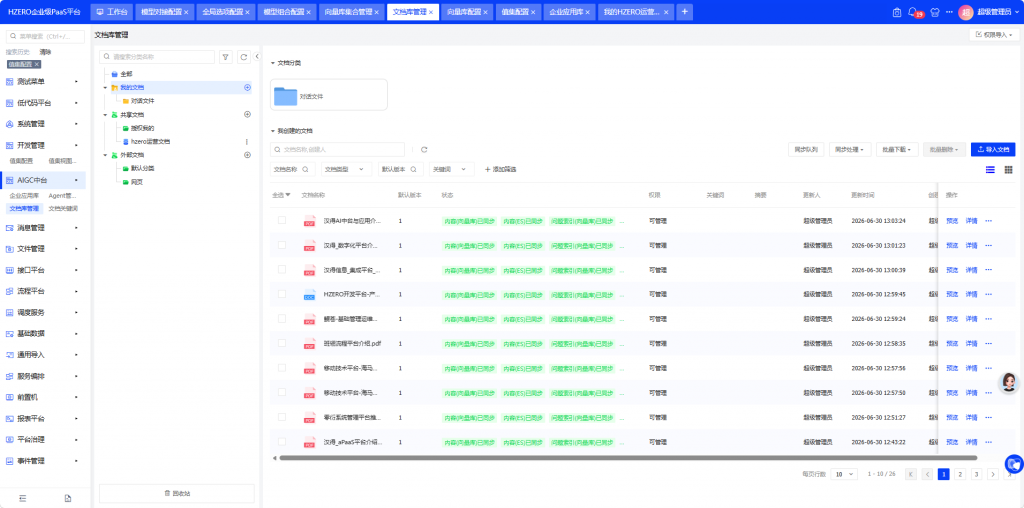
4.2 检查文档同步状态
清理索引后,导航到”文档库管理”页面,你会发现文档的”状态”列仍然显示”已同步到向量库”或”已同步到ES”。这是因为文档表中记录的状态缓存未被清理。重新同步时会自动更新状态,不影响后续操作。
4.3 执行同步
在文档库管理页面,可以选中一个或多个文档,点击”同步处理” > “选择同步” 进行单文档测试,或点击”全部同步”批量重建索引。系统会重新读取文档内容、切片、调用向量模型生成embedding并写入新的ES索引。
五、常见问题一:向量维度不匹配(Failed: X document(s) failed to index)
5.1 错误现象
在执行文档同步时,右下角弹出红色错误提示:
“资源同步失败 – 内容同步(向量库) – Failed: 10 document(s) failed to index.”
点开文档的同步信息详情,可以看到更具体的错误:
“The [dense_vector] field [embedding] in doc … has a different number of dimensions [1024] than defined in the mapping [2048].”
5.2 原因分析
ES向量索引的mapping中预定义的向量维度是2048(来自原来的豆包模型),但新模型阿里 text-embedding-v4 输出的向量维度是1024。写入时维度不一致,ES拒绝写入。
5.3 解决方法
按照第四节的步骤,在值集中添加1024维度 → 新建维度为1024的模型账户 → 新建组合 → 设为默认 → 删除旧索引 → 重建同步。新索引创建时会自动按新模型维度建立mapping。
⚠️ 关键注意点:向量维度一旦在模型对接账户中配置,后续不可修改。如果要换维度,只能新建一个模型对接账户,不能编辑原有的。
六、常见问题二:PDF图片识别失败(调用HKMS执行文件切片时发生错误)
6.1 错误现象
执行同步后,右下角弹出错误提示:
“调用HKMS执行文件切片时发生错误: I/O error on POST request for http://hzero-hkms:18080/kms/loader/v2/process_file: Timeout”
或:
“调用HKMS执行文件切片时发生错误: Failed: 67/19 document(s) failed to index.”
查看hzero-hkms容器日志,会发现大量WARNING级别的报错:
“response from Hzero API: {failed: True, code: haip.error.arrange.account_config.not_exists, message: ‘模型{0}不可用,请重新选择其他模型。’}”
6.2 原因分析
这个错误的根本原因不是向量模型的问题,而是PDF处理流程中的一个关键环节:
HKMS在执行文档切片(process_file)时,对于PDF文件中的图片,需要调用一个多模态大模型来解释图片内容(图片说明/OCR)。这个图片识别走的是”全局选项配置”中的”图片识别模型”配置,而不是”默认对话模型”。
如果你的”图片识别模型”组合中配置了已下架或不可用的模型(例如kimi-2.5已下架),图片识别就会失败,进而导致整个文档切片处理异常并超时。
6.3 解决方法
步骤1:在”模型组合配置”中找到当前配置为”图片识别模型”的那个组合。
步骤2:检查该组合中包含的模型是否都可用(特别是有没有已经下架的模型)。
步骤3:如果某个模型已不可用,在组合中禁用它或切换到其他可用的模型(例如doubao-seed-1.8)。
步骤4:重新测试组合是否可用(点击测试按钮)。
步骤5:确认”默认对话模型”不需要修改,可以继续保持使用纯文本对话模型(如deepseek-V3),因为”图片识别模型”是独立配置的,两者互不干扰。
步骤6:重新执行文档同步(选择同步或全部同步)。
七、完整操作流程一览
以下是更换向量模型后、重建索引成功的完整操作流程,按顺序执行即可:
| 序号 | 步骤 | 操作位置 | 说明 |
| 1 | 确认新模型的向量维度 | 模型文档/阿里官网 | 例如阿里 text-embedding-v4 = 1024 维 |
| 2 | 值集中添加新维度(如需) | 值集管理 > 向量模型维度 | 如果维度选项不存在,先添加 |
| 3 | 新建模型对接账户 | 模型对接配置 | 选择模型分类、类型、维度 |
| 4 | 新建模型组合 | 模型组合配置 | 关联刚建的模型账户 |
| 5 | 设为默认文本向量模型 | 全局选项配置 | 修改默认文本向量模型配置项 |
| 6 | 检查图片识别模型是否可用 | 模型组合配置 | 若有已下架模型,更换或禁用 |
| 7 | 释放并删除旧向量索引 | 向量库集合管理 | 逐条释放后再删除 |
| 8 | 执行文档同步 | 文档库管理 | 选”选择同步”测试或”全部同步”批量 |
| 9 | 验证知识问答功能 | AI对话/知识问答 | 确认能正确检索文档内容 |
八、避坑指南与关键要点
8.1 关于向量维度
向量维度一旦在模型对接账户中配置,后续不可修改
如需更改维度,只能新建一个模型对接账户
新建账户时如果维度选不到,先去值集管理中添加
同一个向量模型可能有多个维度版本,务必确认正确的值
8.2 关于模型组合中的已下架模型
AI模型厂商经常下架旧版本模型,下架后虽然账户还在,但实际调用会失败
检查模型组合时,不仅要看是否有模型,还要看模型是否仍然可用
如果一个组合中有多个模型,其中一个不可用会导致整个组合失败吗?取决于策略配置。轮询策略下如果轮询到已下架模型就会失败,建议禁用或移除已下架的模型。
8.3 关于图片识别模型的独立配置
PDF中的图片识别走的是”图片识别模型”配置,不是”默认对话模型”
这意味着你可以在对话中使用纯文本模型(如DeepSeek-V3),同时使用多模态模型处理PDF图片
两者互不干扰,不需要为了文档同步而修改默认对话模型
8.4 排查思路总结
如果文档向量索引重建失败,建议按以下顺序排查:
第一步:查看hzero-hkms的容器日志,找到具体的错误信息
第二步:如果是”dimensions mismatch”相关错误,检查向量维度是否匹配
第三步:如果是”file切片超时”或”model not exists”相关错误,检查图片识别模型的配置
第四步:修复后重新执行同步测试
九、总结
更换向量模型后重建索引,本质上是处理两个层面的问题:一是”数据格式”层面——新模型输出的向量维度与旧索引mapping不一致;二是”模型调用”层面——图片识别依赖的模型是否可用。
两个问题都解决后,文档向量索引重建和知识问答功能就能正常工作。希望本文能帮助你在遇到类似问题时,更快地定位和解决问题。
—END—
附图: